Agent: What, Why, How.

Agent is a core concept in AI. As Large/Language Models (LMs) become popular, people are talking about building autonomous agents based on LMs.
Executive Summary
The learner and decision maker is called the agent.
The whole field of AI is built around agents.
Agents require planning capacity.
Agents are built with data and/or model.
Ground-truth-in-the-loop
Hard or impossible to satisfy multi-objectives and/or multi-constraints
LMs are approximations.
Modular, specialized, “small” models
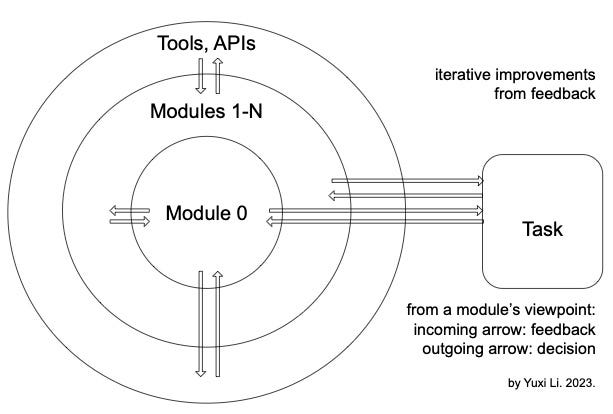
Iterative improvements from feedback
AI is different from IT.
What is an agent?
The learner and decision maker is called the agent.

The definition and the figure are from Reinforcement Learning: An Introduction. Agent is a classical, core concept in AI.
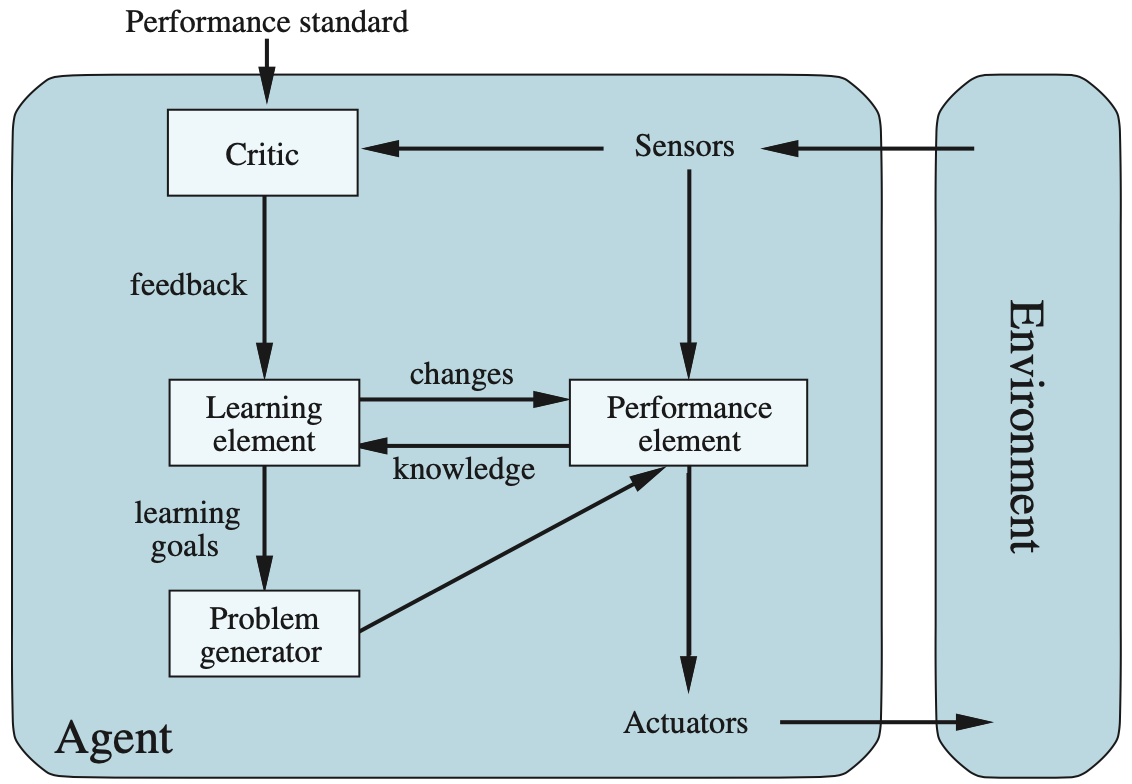
The following definitions, discussion and figure are from the AI book Artificial Intelligence: A Modern Approach. An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators. For each possible percept sequence, a rational agent should select an action that is expected to maximize its performance measure, given the evidence provided by the percept sequence and whatever built-in knowledge the agent has.
A task environment specification includes the performance measure, the external environment, the actuators, and the sensors. In designing an agent, the first step must always be to specify the task environment as fully as possible. Task environments vary along several significant dimensions. They can be fully or partially observable, single-agent or multi-agent, deterministic or nondeterministic, episodic or sequential, static or dynamic, discrete or continuous, and known or unknown.
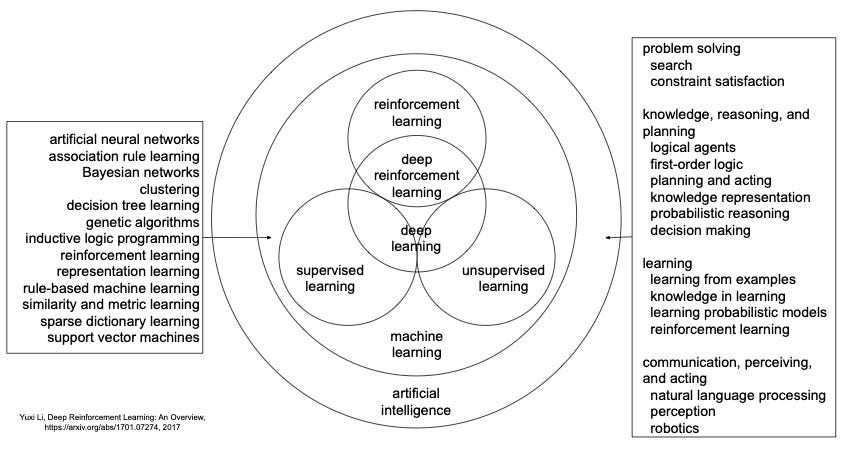
The whole fields of RL and AI are constructed around agents: relevant techniques to make agents feasible/optimal, from heuristic search like A*, to prediction methods like decision trees and neural networks, to decision frameworks like planning and Bayesian methods, to fields for perception (computer vision), communication (natural language processing) and action (robotics). For more details, check the RL book and the AI book.
Why agents?
Humans are improving tools for better productivity, in the progress of civilization, in particular, during the eras of information and intelligence revolutions. Automation of tools is one goal of humankind, and is also one goal of AI. Researchers and developers have been working hard on it from several decades ago.
For simple tasks like ordering a pizza, some app may be good enough and we can choose among many toppings. Moreover, we may not rely entirely on an LM which may hallucinate sometimes to order food automatically. What if it orders a pizzeria instead of a pizza?
For complex tasks, in particular, those require multiple steps, current LMs may not be ready yet, since they are not trained for planning. The problem is, if an LM makes some mistakes, and if the LM is the most competent in the system, then how to fix the problem?
A simple and straightforward solution is to have human-in-the-loop. In case an AI can not solve a problem, resort to a human. In this case, we should not call it an “autonomous” agent though.
Agents require planning capacity
It is essential for a component in the system to have the planning capacity. Most LMs acquire some planning capacity during pre-training, maybe through “emergence”, but not by explicit training, which is an innate shortcoming. Auxiliary methods may remedy it to some extent, e.g, using ReAct to improve prompts, which do not attempt to improve the LM itself. However, pre-training and/or fine-tuning with planning capacity are likely the ultimate solution. There may be tradeoffs between performance vs cost, which calls for more investigations.
In A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis, WebAgent combines new pre-trained LM HTML-T5 for planning and summarization and Flan-U-PaLM for grounded code generation. WebAgent considers modularity and (small) specialized LMs. HTML-T5 has not done iterative improvements from feedback yet. WebAgent treats feedback as future work.

In Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization, Retroformer combines an actor LM to generate reasoning thoughts and actions and a retrospective LM to generates verbal reinforcement cues to assist the actor in self-improvement by refining the actor prompt with reflection responses. RetrospectiveLM makes iterative improvements from feedback. However, it relies on a fixed Actor LM, which may make mistakes some times.

There are recent work considering agency/planning during pre-training, e.g., Gato: A Generalist Agent, Adaptive Agent: Human-Timescale Adaptation in an Open-Ended Task Space, RT-1: Robotics Transformer for Real-World Control at Scale, RT-2: New model translates vision and language into action, and SMART: Self-supervised multi-task pretraining with control transformers.
There are also works with iterative improvements of (language) models, e.g., CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning, Human-level play in the game of Diplomacy by combining language models with strategic reasoning, Language Models Can Teach Themselves to Program Better, LeanDojo: Theorem Proving with Retrieval-Augmented Language Models, Offline RL for Natural Language Generation with Implicit Language Q Learning, Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning, RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation.
Agents are built with data and/or model
Classical planning needs a perfect model. For example, finding the shortest path on a graph, where all graph information is available. From the AI book, “Classical planning is defined as the task of finding a sequence of actions to accomplish a goal in a discrete, deterministic, static, fully observable environment.” The AI book also discusses about stochastic environments, in which outcomes of actions have probabilities associated with them: Markov decision processes, partially observable Markov decision processes, and game theory, and shows that reinforcement learning allows an agent to learn how to behave from past successes and failures.
Classical operations research (OR) like dynamic programming and classical optimal control like model predictive control (MPC) also need a perfect model to specify a mathematical formulation.
In the era of data, an agent can learn a planning policy from data, sometimes without a model, by 1) imitation learning with (experts’) demonstrations; 2) model-free reinforcement learning (RL), with experience data collected by interacting with the world; 3) model-based RL, with data from interactions and from the model; 4) offline RL with data collected offline. A model-based approach may be more efficient.
Planning, operations research and optimal control are embracing adaptive approaches. One prominent example is AlphaZero, where Monte Carlo tree search (MCTS) together with value function and policy reduces the astronomical search space significantly. See Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control. We enjoy a synergy between the classical model-based and the modern data-driven methods.
Supervised fine-tuning in LMs is imitation learning. Lessons from AlphaGo show that imitation learning is not enough though.
In model-based RL, the model makes iterative improvements from new data. When an LM is used as an agent, if the LM is not perfect yet, it needs to make improvements from new data too.
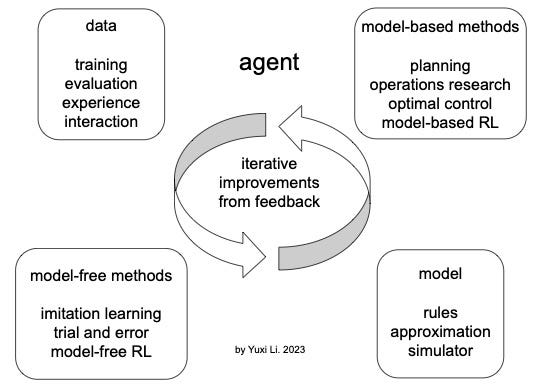
For a concrete problem, before relying on a fixed LM, we need to examine if the performance is statistically better than using a customized model or simulator. Even so, we may have to bridge the LM-to-real gap, if we care about correctness or even optimality, similar to that we won’t deploy a robot purely trained with a simulator.
Iterative improvements from feedback will be the key for further progress of LMs-based agents.
Where are LMs in the above figure?
LMs are Approximations
LMs are approximate planners. LMs are approximate models. LMs are approximate simulators. We need to bridge the LM-to-real gap. We need to handle mistakes.
As in AgentBench: Evaluating LLMs as Agents, LMs can not solve problems perfectly yet, e.g., for the House-Holding (Alfworld) problem, GPT-4 can solve 78% problems successfully. This is far from being a good enough agent “brain”. To make an LM like GPT-4 competent as the agent brain, (much) efforts are required to improve the success rate close or equal to 100%. Ideally, we should have a benchmark for each type of agent, and cover all potential corner cases. Otherwise, the agent needs to learn from potential mistakes, which may be costly or dangerous.
LMs are still struggling with fundamental issues, e.g., besides the popular hallucination, GPT-4 can not solve all 3 or 4-digit multiplications, GPT-4 together with Tree of Thoughts can not solve all Game of 24 and OthelloGPT can not guarantee legal moves. Such fundamental issues translate to incompetency in planning capacity.
To leverage LMs in building agents, we need to handle mistakes by LMs, either by pre-training or fine-tuning to improve planning capacity, e.g., WebAgent and Retroformer, and likely with iterative improvements from feedback. Auxiliary methods like ReAct may mitigate the problem.
RL is a solution framework for sequential decision making, in particular, for building agents. With the breakthrough of AlphaGo series, we have been enjoying significant progress in RL. However, applying RL in real life remains challenging. See Reinforcement Learning in Practice: Opportunities and Challenges.
There are potentially many ways RL and LMs work together to build more and more successful agents, e.g., LMs help provide better representation for RL and RL helps improve planning capacity for LMs. See a brief survey with perspective Iterative improvements from feedback for language models. See a survey Foundation Models for Decision Making: Problems, Methods, and Opportunities and a workshop Foundation Models for Decision Making: NeurIPS 2023, NeurIPS 2022.
Respect basic principles
Let’s talk about some basic principles.
Principle: Ground-truth-in-the-loop.
Relying solely on self-generating training data and self-evaluation violates the principle of ground-truth-in-the-loop. (Current) LMs are not ground truth. A mixture with reliable data and/or feedback, e.g., by augmenting with knowledge graph or search engine, may mitigate the problem.
Principle: Multi-objective optimization usually will not optimize all objectives. The more and the tighter constraints, the less chance to find a feasible solution.
Attempts to deal with many or even all tasks with a single model do not respect the basic optimization principle for multi-objective and/or multi-constraints. In short, AGI with a single model is a wrong goal. Employ modularity and benefit from collaboration of specialized, top-expert-level modules.
Principle: Iterative improvements from feedback.
Relying on a fixed LM, or an LM updated every month or even longer, sacrifices the benefits of iterative improvements from feedback. Many, if not all, autonomous agents, should not rely on a single, (semi-)fixed, imperfect LM. It is essential for a component in the system to make iterative improvements from feedback. WebAgent and Retroformer as discussed above are two examples.
How to make agents work?
A reader may ask: You talk about planning capability, data, model, approximation, ground-truth-in-the-loop, modular, specialized and “small” models, iterative improvements from feedback. How to make agents work?
The above is actually the answer.
In more detail, the answer is basically in two books: Reinforcement Learning: An Introduction and Artificial Intelligence: A Modern Approach. In the following picture, a subset of solution methods may be relevant to your agents, depending on the agents and which approach you take to build it. This is particularly true when an LM can not handle all issues for your agent, which is almost surely true.
AI vs. IT
There are various types of AI applications. One extreme is “Critical AI”, for which it is too costly or even dangerous to make mistakes, e.g., autonomous driving, health care, etc. Another extreme is “Don’t care mistakes AI”, which may even treat mistakes as creativity. Most cases are “Somewhere in between AI”. We have to answer the question: How to handle mistakes from AI? If an LM can not handle something (perfectly), e.g., hallucination and planning, it may be hard for most, if not all, people to handle.
AI is different from IT. IT systems are basically transparent: WYSIWYG (what you see is what you get). A problem may be fixed easily or with some efforts. AI systems may be blackboxes, esp. with deep learning. If an AI system encounters a problem, it is potentially a hard problem, or even an open problem — it may not be simply fixable as in an IT system.
As the figure below shows, there are complex dependencies among AI software engineering procedures. From Software Engineering for Machine Learning: A Case Study, ICSE 2019. How much have LMs changed it? Likely little or even none. See, e.g., How is ChatGPT's behavior changing over time? The whole AI system needs to make iterative improvements from feedback.

Moreover, an Andreessen Horowitz blog argues that AI creates a new type of business, combining both software and services, with low gross margins, scaling challenges, weak defensive moats, caused by heavy cloud infrastructure usage, ongoing human support, issues with edge cases, the commoditization of AI models, and challenges with data network effects.
Optimistic Outlook
AI has been making steady progress and making impressive achievements like AlexNet, AlphaGo and ChatGPT. LMs draw a picture full of hope. Let’s walk step by step and make the dream come true by making iterative improvements from feedback.