
How would Deepmind Gemini work?

Deepmind will launch Gemini soon, reportedly.
How would it work?
Let’s see what Deepmind/Google have published?
BRET T5, LaMDA, PaLM, Sparrow, Chinchilla, Gopher
PaLM-E: An Embodied Multimodal Language Model
Flamingo: a Visual Language Model for Few-Shot Learning
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
Human-Timescale Adaptation in an Open-Ended Task Space
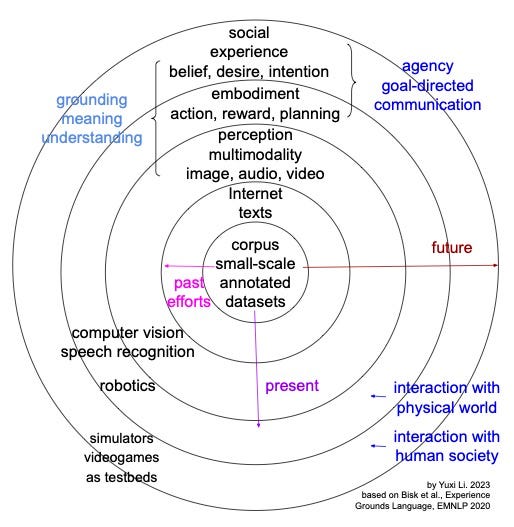
From the above sample of papers, we can see, besides “normal” language models, Deepmind has been working on multimodality, embodiment and interaction, resonating with the school of thought as illustrated by the figure below, which shows five levels of World Scopes based on Experience grounds language: small scale Corpus (our past) for corpora and representations, large scale Internet (most of current NLP) for the written world, Perception (multimodal NLP) for the world of sights and sounds, Embodiment and action for interaction with physical world, and Social world for interaction with human society.
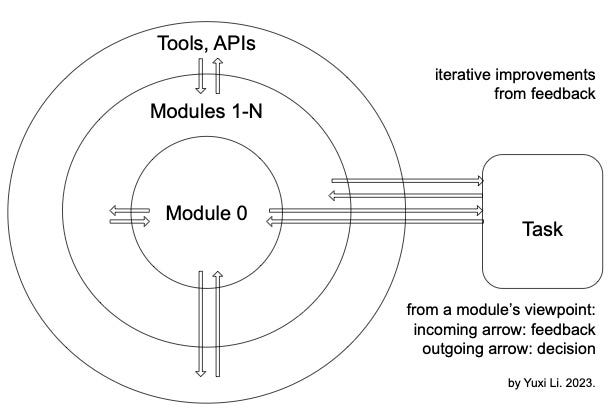
Iterative improvements from feedback is (arguably) a universal principle for building a successful system, for bridging the LM-to-real gap, attaining grounding, agency, optimality and adaptivity, based on ground-truth-in-the-loop, i.e., reliable training data and feedback.

It is interesting to see that Deepmind is working on simulation explicitly, UniSim: Learning Interactive Real-World Simulators, which is much more promising than relying on a world model or a simulator resulting from implicit “emergence” from a language model. However, note: General intelligence with a single model is about approximation. The same is true for a general simulator. That is, it is hard, if not impossible, for a single simulator to precisely simulate all scenarios. Bounded rationality is also a concern.
Deepmind is well-known for its prowess in deep reinforcement learning (RL). Needless to mention AlphaGo and many works, Deepmind has already explored deep RL in LLMs/foundation models, e.g., Adaptive Agent, Say Can, etc. RL is promising for iterative improvements from feedback for LLMs, however, it is still in an early stage of research, thus it is hard to predict how much deep RL will be deployed in Gemini.
Prediction is very difficult, especially if it's about the future. Let’s see how much Gemini will overlap with what we discuss here, in particular, grounding, agency, multimodality, embodiment, interaction, modularity and iterative improvements from feedback, as in the two figures above.
Watch a video on YouTube: