
Iterative improvements from feedback for language models

Executive Summary

This “blog” is converted from a PDF file with 20 pages content excluding reference.
Iterative improvements from feedback for language models
Abstract
Iterative improvements from feedback is a gen- eral approach for many, if not all, successful systems. Ground-truth-in-the-loop is critical. Language models (LMs) like ChatGPT are phenomenal, however, there are still issues like hallucinations and a lack of planning and controllability. We may leverage LMs’ competence of language to handle tasks by prompting, fine-tuning, and augmenting with tools and APIs. AI aims for optimality. (Current) LMs are approximations, thus induce an LM-to-real gap. Our aim is to bridge such a gap. Previous study shows that grounding, agency and interaction are the cornerstone for sound and solid LMs. Iterative improvements from feedback is critical for further progress of LMs and reinforcement learning is a promising framework, although pre-training then fine-tuning is a popular approach. Iterative updates are too expensive for monolithic large LMs, thus smaller LMs are desirable. A modular architecture is thus preferred. These help make LMs adapt to humans, but not vice verse. We discuss challenges and opportunities, in particular, data & feedback, methodology, evaluation, interpretability, constraints and intelligence.
1. Introduction
Iterative improvements from feedback appears as a universal principle, e.g., gradient descent in optimization, expectation-maximum, boosting, and temporal difference learning in AI, trial and error in animal learning, policy iteration in dynamic programming, close-loop feedback control, (agile) software development, free market for economy, and evolution of our humankind.
Principle: Most, if not all, successful systems make iterative improvements from feedback.
A successful system should be built on ground truth, although it may start with a learned, approximate model or simulator. For an AI system, this includes trustworthy training data and evaluation feedback, and when planning is involved, a reliable world model. For a system with human users, human data and feedback are paramount, and human-in-the-loop is relevant or may be a must. Prominent AI systems like search engines and large language models are built on valuable data, from the Internet and from user feedback. AlphaGo series and games AI have made remarkable achievements, where a perfect game rule, i.e. a model, is a core factor: it can generate high quality or perfect data including game scores. We should not deploy an AI system trained purely from a simulator, especially for high stake systems like healthcare, robotics and autonomous vehicles. We evaluate a system with ground truth for dependable performance results. A system should not self-evaluate itself, e.g., a student should not self-grade the assignment. Section 4 discusses more about approximation. Section 6 discusses more about data and evaluation.
Principle: Ground-truth-in-the-loop.
Language models (LMs), in particular, Chat-GPT (OpenAI, 2022a) and GPT-4 (OpenAI, 2023a), have being taken us by storm. Both opportunities and challenges abound for LMs, with vast potential applications, and issues like hallucinations and a lack of planning and controllability, see e.g., OpenAI (2023a) and OpenAI (2023b). In this article, we discuss if and how the principle of iterative improvements from feedback can be applied to LMs.
Mahowald et al. (2023) study LMs’ linguistic (“knowledge of rules and patterns of a given language”) vs functional (“a host of cognitive abilities required for language understanding and use in the real world”) competence and experimental results show impressive yet imperfect linguistic competence, however, at the same time, failures on tests requiring functional competence .
Premise: Current LMs have strong linguistic but weak functional competence.
Then we can leverage LMs’ competence as a good model of language. Moreover, we can manage to improve the functional competence, e.g., factuality, safety, planning and controllability. Prompting is a natural way to utilize LMs, based on the capacity of in-context learning (Brown et al., 2020). Fine-tuning an LM can further improve its expertise. A parameter efficient approach makes fine- tuning large LMs feasible considering the cost. Integrating LMs with tools and APIs can achieve various functionalities.
There are more and more "small" LMs around 10B parameters or less. They are actually very large and in a relative sense. When resources become cheaper, larger models are more affordable. When models become stronger, smaller models may be good enough. Being environment friendly, smaller models are preferred.
Most LMs are trained without optimizing for downstream tasks. Most works utilizing LMs focus on feasibility and correctness. There is a room for further improvements w.r.t. optimality.
Purpose: AI aims for optimality.
To achieve optimality for an AI system, com- putational bounded rationality leads to approxima- tions (Gershman et al., 2005). Popular methods for general intelligence recently are learning to learn, like transfer / few-shot / multi-task / meta-learning. This boils down to finding a feasible/optimal solution with multiple objectives and/or multiple constraints. Multi-objective optimization usually will not optimize all objectives. The more and the tighter constraints, the less chance to find a feasible solution. Also, with negative transfer, the previous knowledge may interfere with later learning.
Premise: General intelligence is approximation.
A general purpose AI system approximates the underlying world model, i.e., there is a gap between a learned and the real model. We dub this “LM-to-real gap” or LM2real gap or LM to reality gap, following recent study on simulation to reality gap or sim-to-real gap in robotics and RL communities. LMs can represent both Language Models and Large Models, which also include foundation models (Bommasani et al., 2022). Our goal is to bridge such a gap. See Section 4 and 6.5 about approximation and constraints, respectively. Section 6.6 discusses more about intelligence.
Purpose: Bridge LM-to-real gap.
As in Bisk et al. (2020), a language describes the physical world and facilitates the social interactions, and we can’t learn language from a radio (Internet), from a television, or by ourselves. Grounding and agency from interactions with the physical and social world are indispensable for LMs.
Premise: Grounding, agency and interaction are indispensable for sound and solid LMs.
Among LMs, GPT-4 is by far regarded as the most capable. However, it is too large to itera- tively improve relatively frequently. On the contrary, small LMs are improving, even surpassing GPT-4 in certain tasks, and are conducive to iterative improvements from feedback. To satisfy certain performance thresholds, we may have to limit the number of tasks, so that they can be solved together to attain a feasible solution. This justifies a modular approach: each module handles certain tasks, and all collaborate together. Moreover, issues like privacy and compliance with regulations may favour modularity. Modularity and small LMs will become competent and versatile.
Premise: Modularity and small LMs facilitate iterative improvements from feedback.
Prompt engineering, a popular approach to using LMs, shows how humans have to adapt to AI by deciphering how to use AI, e.g., Zamfirescu-Pereira et al. (2023) study how non-AI experts try and fail to design prompts. This does not align well with one goal of developing AI: AI should adapt to humans. AI should figure out a human’s intention and help achieve the goal. Although humans may have to adapt to tools to some extent, LMs are at their early stage, e.g., as a user interface, there is a large room for LMs to improve.
Purpose: AI adapts to humans, not vice versa.
Iterative improvements from feedback can achieve optimality and improve adaptability of AI to humans. Reinforcement learning (RL) (Sutton and Barto, 2018) is a promising framework to learn from feedback and for adaptive control, and thus to advance language models. AlphaGo (Silver et al., 2016) set a landmark in AI by defeating a world champion in Go, using self-play RL to make iter- ative improvements. It is desirable to harness the achievements in AlphaGo and games AI.
Premise: Reinforcement learning is promising for iterative improvements from feedback.
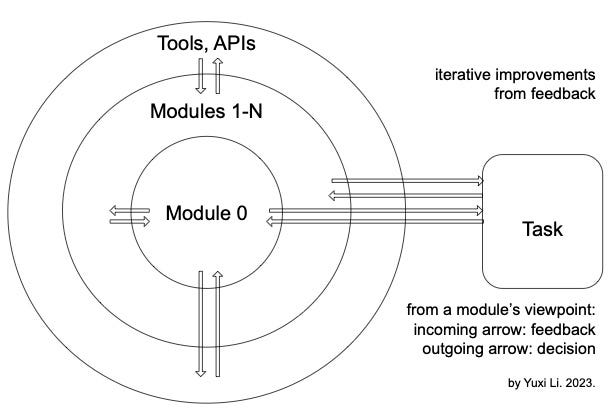
See Figure 1 for a brief illustration. In the following, we discuss the above principles, premises and purposes in more detail.
2. Background
2.1 Experience grounds language
As illustrated in Figure 2, Bisk et al. (2020) define five levels of world scopes. Together with texts, perception, embodiment and social interaction con- textualize a language with the world.
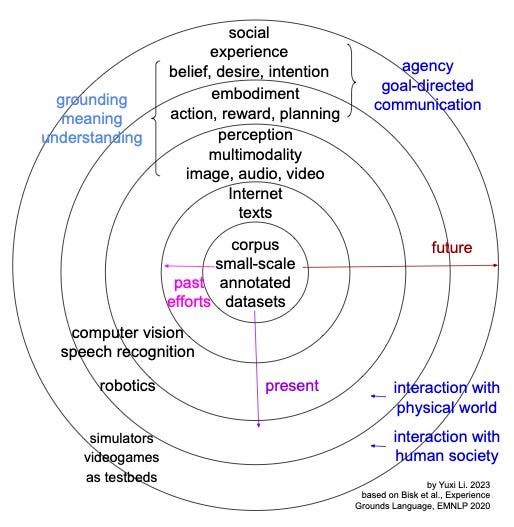
Grounding is about meaning, understanding, and being appropriate and consistent with the context. Embodiment is about interaction, with action, reward and planning, in a physical world. Social interaction is about communication in human society. Agency, with belief, desire and intention, is about acting to achieve goals. An agent is a learner and decision maker (Sutton and Barto, 2018).
As discussed in Carta et al. (2023), symbol grounding makes actions based on the internal symbol system to be affordable in the environment, direct grounding associates elementary symbols with high-dimensional perceptions, and grounding transfer associates abstract concepts with elementary symbols. Carta et al. (2023) propose functional grounding to manipulate internal symbols to model, predict and control external processes.
In Smith and Gasser (2005), the embodiment also includes social interaction: “The embodiment hypothesis is the idea that intelligence emerges in the interaction of an agent with an environment and as a result of sensorimotor activity.” Smith and Gasser (2005) summarizes six lessons from babies for the development of embodied cognition: be multimodal, be incremental, by physical, explore, by social, and use language. Bohg et al. (2017) and Ostrovski et al. (2021) show the importance of active perception, following Held and Hein (1963). Lampinen et al. (2023) show evidence for passive learning of active causal strategies, however, ad- mit that active learning is more beneficial and con- founding is challenging for passive learners. See also Roy et al. (2021).
Bisk et al. (2020) prioritize grounding and agency and highlight the importance of physical and social context of language. Computer vision, speech recognition, robotics, simulators and videogames facilitate investigation of language.
2.2 Reinforcement learning
Reinforcement learning is a general framework for sequential decision making with broad appli- cations (Bertsekas, 2019; Littman, 2015; Powell, 2021; Sutton and Barto, 2018; Szepesvári, 2010). An RL agent interacts with the environment over time to learn a policy, by trial and error, that maximizes a long-term, cumulative reward. At each time step, the agent receives an observation, selects an action to be executed in the environment, following a policy, which is the agent’s behaviour, i.e., a mapping from an observation to actions. The environment responds with a scalar reward and by transitioning to a new state according to the environment dynamics. Deep RL is at the intersection of deep learning (Bengio et al., 2021; LeCun et al., 2015; Goodfellow et al., 2016; Schmidhuber, 2015) and RL, with deep learning to approximate functions for value, policy, reward, transition, etc.
RL has remarkable achievements like AlphaGo series (Silver et al., 2016, 2017, 2018), ChatGPT, contextual bandits (Li et al., 2010), Decision Service (Agarwal et al., 2016), ReAgent (Gauci et al., 2019), ride-hailing order dispatching (Qin et al., 2020), AlphaStar (Vinyals et al., 2019) for Star- Craft II, DeepStack (Moravcˇík et al., 2017) and Libratus (Brown and Sandholm, 2017) for Texas Hold’em Poker, Cicero (Bakhtin et al., 2022) for Diplomacy, Gran Turismo Sophy (Wurman et al., 2022), Degrave et al. (2022) for magnetic con- trol of tokamak plasmas, Bellemare et al. (2020) for navigating stratospheric balloons, AlphaTen- sor (Fawzi et al., 2022) for matrix multiplication, and AlphaDev (Mankowitz et al., 2023) for sorting.
See Li (2017) for an overview about deep RL and Li (2022) for discussion about RL in practice.
2.3 Auto-regressive language model
A language model is about the probability distri- bution of a sequence of tokens. In ChatGPT and many LMs, an auto-regressive language model is the probability distribution of next token, given previous tokens, i.e., the conditional probability distribution:
probability(next token|previous tokens).
We focus on such LM here. It can be regarded as a policy, where the “previous tokens” are the state (observation) and the “next token” is the action.
Many problems in natural language processing (NLP) are sequential decision making problems, thus RL is a natural framework. See e.g., Gao et al. (2019); Li (2017).
2.4 Large LMs
GPT stands for Generative Pre-trained Trans- former (Radford et al., 2018, 2019; Brown et al., 2020; OpenAI, 2022a, 2023a). Transform- ers (Vaswani et al., 2017) are the backbone of LMs, featuring self-attention, conducive to long range dependancy and large scale implementation. GPT series and many LM variants are based on deep learning, in particular, self-attention Transformers, self-supervised learning (Balestriero et al., 2023), and pre-training models.
There are many large LMs, e.g., GPT- 3, ChatGPT, GPT-4, BERT (Devlin et al., 2019), RoBERTa (Liu et al., 2023f), T5 (Raffel et al., 2020), LaMDA (Thoppilan et al., 2022), PaLM (Chowdhery et al., 2022), Sparrow (Glaese et al., 2022), Claude (Bai et al., 2022a), Chin- chilla (Hoffmann et al., 2022) Megatron-Turing NLG (Smith et al., 2022), Gopher (Rae et al., 2022), BLOOM (BigScience Workshop et al., 2023), LLaMA (Touvron et al., 2023). The pa- rameter sizes are huge, e.g., 175 billion for GPT-3.
2.5 Specialized LMs
There are many specialized models, e.g., AlphaFold (Tunyasuvunakool et al., 2021), Codex (Chen et al., 2023b), AlphaCode (Li et al., 2022), WebGPT (Nakano et al., 2022), Robotics Transformer (RT-1) (Brohan et al., 2022), BiomedGPT (Zhang et al., 2023a), Clinical Camel (Toma et al., 2023), BloombergGPT (Wu et al., 2023b), FinGPT (Yang et al., 2023a), Med-PaLM 2 (Singhal et al., 2023), MusicLM (Agostinelli et al., 2023), AudioGPT (Huang et al., 2023).
2.6 “Small” LMs
Following LLaMA (Touvron et al., 2023), many “small” LMs appear, with around 10B or smaller, e.g., Alpaca (Taori et al., 2023), Dolly (Conover et al., 2023), Koala (Geng et al., 2023), Vicuna/StableVicuna (Chiang et al., 2023), Chat-GLM (Du et al., 2020; Zeng et al., 2023), StableLM (Stability AI, 2023), Guanaco (Dettmers et al., 2023), Pythia (Biderman et al., 2023), GPT4All (https://github.com/nomic-ai/gpt4all), Open-Assistant (2https://github.com/LAION-AI/Open-Assistant), ColossalChat (You, 2023). “Small” is a relative concept: as software and hardware improve, the current large models may become small. See Kim (2023b) for a list of open sourced fine-tuned LMs.
There are also specilized small LMs, e.g., Gorilla (Patil et al., 2023), a LLaMA-7B-based model, surpassing GPT-4 w.r.t. API calls, TinyStories (Eldan and Li, 2023) for fluent and consistent stories with <10M parameters, and phi-1 (Gunasekar et al., 2023) for good coding performance with 1.3B parameters and 7B tokens.
2.7 Modularity
Mahowald et al. (2023) propose a modular architecture with a language component, a problem solver, a grounded experiencer, a situation modeler, a reasoner, and a goal setter. Laird et al. (2017) discuss the Soar cognitive architecture, including perception, motor, representation, working memory, (procedural, semantic, and episodic) long-term memories, reinforcement learning, semantic learning, episodic learning, and decision procedure.
Modularity may enhance adaptability, compositionality, efficiency, scalability, consistency, robust- ness, and interpretability and mitigate catastrophic forgetting (Pfeiffer et al., 2023).
Karpas et al. (2022) propose Modular Reason- ing, Knowledge and Language (MRKL), a modular, neuro-symbolic architecture to combine LMs, external knowledge sources and discrete reasoning.
Modularity is related to hierarchical learning and planning (Russell and Norvig, 2020), in particular, hierarchical RL (Sutton et al., 1999).
2.8 Discussions & debates about LMs
There are all sorts of discussions & debates, e.g., the dangers of stochastic parrots (Bender et al., 2021), limitation of neural networks (Delétang et al., 2023), limitation of autoregressive models (Lin et al., 2021), lack of causality (Jin et al., 2023), lack of compositionality (Dziri et al., 2023), lack of recursion (Zhang et al., 2023b), limitations (Deshpande et al., 2023; McKenzie et al., 2023) of scaling laws (Kaplan et al., 2020; Hoffmann et al., 2022), model collapse (Shumailov et al., 2023), artificial general intelligence (AGI) (Allyn-Feuer and Sanders, 2023; Bubeck et al., 2023; Marcus, 2023), evaluation of AI (Bur- nell et al., 2023), social norms (Browning and LeCun, 2023), distortion of human beliefs (Kidd and Birhane, 2023), risks and benefits (Goldman, 2023), existential risk (Bengio, 2023), court hearing due to hallucination (Novak, 2023), risk of further concentration of wealth (Chiang, 2023), eight things to know (Bowman, 2023). See more discussions about AI alignment with human value, e.g., Russell (2019); Mitchell (2020); Christian (2021). See surveys, e.g. LMs in practice (Yang et al., 2023b)
3. How to improve LMs?
Besides pre-training and fine-tuning, we can classify methods to improve LMs as follows: a) format/content of prompts: a.1) vanilla text, a.2) multimodality, a.3) augmentation with tools, a.4) integration of advanced techniques like search, learning and coding; b) feedback, b.1) open-loop, no feedback during inference, b.2) close-loop, entirely/mainly from LMs, b.3) close-loop, from environment (games, code interpreter, robotics, etc.) including LMs; c) fixed LMs vs iterative improvements of LMs.
See Table 1 for an illustration of the taxonomy with example methods. Admittedly, methods and models in all the tables are not comprehensive.

3.1 Pre-training
A common approach is pre-training then fine-tuning LMs. In the pre-training stage, LMs, and foundation models (Bommasani et al., 2022) in general, are trained on broad data, usually with self-supervised learning (Balestriero et al., 2023) at scale, being widely adaptive to downstream tasks. Table 2 compare several pre-training models.

Radford et al. (2018) introduce generative pre- training for LMs, which could be regarded as “GPT-1”. Radford et al. (2019) introduce GPT- 2, an unsupervised multitask learning LM. Brown et al. (2020) introduce GPT-3, a few-shot learning
LM, popularizing the concept of in-context learn- ing (Dong et al., 2023). OpenAI (2022a) introduces ChatGPT and OpenAI (2023a) introduces GPT-4.
Devlin et al. (2019) introduce Bidirectional En- coder Representations from Transformers (BERT). See a survey about BERT Rogers et al. (2020). Raf- fel et al. (2020) introduce Text-to-Text Transfer Transformer (T5).
There are foundation models for control/RL. Gato (Reed et al., 2022) is a generalist policy for multi-task, multi-modality, and multi-embodiments. Adaptive Agent (AdA) (Adaptive Agent Team et al., 2023) is an RL foundation model adaptive to a vast and diverse task space at human timescale. Sun et al. (2023b) propose self-supervised multi-task pre-training with control transformer (SMART).
3.2 Fine-tuning
Fine-tuning further improve LMs. Table 3 compare several fine-tuning models.

Large LMs like GPT-3 have a huge number of parameters so that it is prohibitively expensive to make a full refinement. Fortunately, parameter efficient fine-tuning (PEFT) methods, like Low-Rank Adaptation (LoRA) (Hu et al., 2021) and quantized LoRA (QLoRA) (Dettmers et al., 2023) have shown that it is possible to fine-tune a small number of parameters while achieving comparable performance. Liu et al. (2022) show that PEFT outperforms in-context learning. See more studies about PEFT, e.g., Mao et al. (2022), He et al. (2023), Ding et al. (2023), Chen et al. (2023a).
RL from human feedback (RLHF) is adopted by many LMs. Christiano et al. (2017) propose RLHF, i.e., by defining a reward function with preferences between pairs of trajectory segments, to tackle the problems without well-defined goals and without experts’ demonstrations, and to help improve the alignment between human value and the objective of RL system. Ouyang et al. (2022) propose to fine-tune GPT-3 with human feedback, in particular, with RL, to follow instructions for better alignment with human value. ChatGPT, after pre-training, conducts 1) supervised fine-tuning (SFT), 2) reward model learning, 3) reinforcement learning (OpenAI, 2022a), where the last two steps constitute RLHF.
Instruction following or instruction tuning includes supervised fine-tuning and RLHF, both of them are imitation learning; see Section 6.1.
Christiano et al. (2017), Ouyang et al. (2022) and many RLHF papers use Proximal Policy Optimization (PPO) (Schulman et al., 2017) to optimize a policy. Ramamurthy et al. (2023) propose Nat- ural Language Policy Optimization (NLPO). Zhu et al. (2023) propose Advantage-Induced Policy Alignment (APA).
RLHF plays a critical role in human alignment and facilitates learning of the objective function. ChatGPT collects human data. Bai et al. (2022b) propose Constitutional AI with rules or principles and RL from AI Feedback (RLAIF) with super- vised learning and RL to reduce the reliance on human involvements in learning an LM. Glaese et al. (2022) also design rules in Sparrow.
Lee et al. (2021) propose unsupervised pre- training and preference-based learning via relabeling experience (PEBBLE) to improve the efficiency of human-in-the-loop feedbacks with binary labels, i.e. preferences, provided by a supervisor. Liu et al.(2023b) propose Chain of Hindsight (CoH) to convert all feedback into sentences. Wu et al. (2023c) propose fine-grained RLHF to learn from and mul- tiple reward models, each of which associates with a specific error category with dense signals at seg- ment level. Human Feedback Gives Better Rewards for Language Model Training Rame et al. (2023) propose rewarded soups to handle the heterogeneity of diverse rewards by interpolation of multiple strategies to achieve Pareto-optimal alignment.
Rafailov et al. (2023) propose Direct Preference Optimization (DPO) without reward modelling or RL. However, DPO applies only to the Bradley-Terry model underling current RLHF to estimate score functions from pairwise preferences. There may be other ways to handle human preference and non-preference ways to handle value alignment, e.g., Knox and Stone (2008) uses ratings to transmit human knowledge to an RL agent.
LIMA (Zhou et al., 2023a) shows the importance of a high-quality pre-training model and carefully curated instruction data.
Zhang et al. (2021) survey human guidance for sequential decision-making. Wirth et al. (2017) present a survey of preference-based RL methods. Lambert et al. (2022) is a blog about RLHF. RL from human feedback goes back at least to Knox and Stone (2008).
Goldberg (2023) discusses that a “traditional” language model is trained with natural text data alone, while ChatGPT is not traditional any more: it is augmented with instruction tuning, programming language code data, and RLHF.
3.3 Prompting
Prompts serve as the user interface for LMs. In this sense, most methods are about improving prompts, in particular, those with fixed LMs. Table 4 compare several methods to improve prompts.

Here we discuss open-loop methods, which do not benefit from feedback, e.g., Chain-of-Thought (CoT) (Wei et al., 2022), Least-to-Most prompting (Zhou et al., 2023b), Zero-Shot Planners (Huang et al., 2022a) and Chameleon (Lu et al., 2023a). Human users may improve their prompt engineering skills after seeing outputs of prompts. However, such methods do not improve themselves based on such feedback.
There are works for prompt optimization / automation, e.g., prefix-tuning (Li and Liang, 2021), prompt tuning (Lester et al., 2021), symbol tuning (Wei et al., 2023), RLPrompt (Deng et al., 2022), TEMPERA (Zhang et al., 2023d), PromptPG (Lu et al., 2023b). Such methods improve prompts in an “offline” manner, i.e., not interactively while using prompts. Note, prefix-tuning and prompt tuning are classified as parameter efficient fine-tuning, in e.g., Ding et al. (2023), He et al. (2023), Ruder et al. (2022). See a survey (Liu et al., 2023e).
The drawbacks of prompting are inefficiency, poor performance, sensitivity to prompt, and lack of clarity (Ruder et al., 2022). It also lacks adaptability to users, so that uses have to figure out how to use LMs with prompt engineering. Users’ heavy reliance on prompt engineering implies that LMs are not good enough; otherwise, an LM can adapt to a user and guide a user how to use the LM.
To extract the capacity of LMs, prompts integrate sophisticated methods like 1) search, e.g., Tree of Thought, 2) coding, e.g., Code as Policies and PAL, and 3) planning with code, e.g., AdaPlanner and Voyager, as in next section.
3.4 Close-loop feedback with self-reference to fixed LMs
Close-loop methods benefit from feedback and make improvements. Feedback may come from external sources like games, code interpreter and robotics. In the following, we discuss recent work with close-loop feedback with fixed LMs. Table 5 presents a brief comparison.

Multimodality and embodiments may integrate with visual Transformers and pre-training for perception, like Contrastive Language-Image Pre-training (CLIP) (Radford et al., 2021), diffusion model (Rombach et al., 2022), or ControlNet (Zhang and Agrawala, 2023). PaLM-E (Driess et al., 2023) is an embodied multimodal LM.
Liang et al. (2023b) propose High-Modality Multimodal Transformer (HighMMT) to handle 10 modalities: text, image, audio, video, sensors, pro- prioception, speech, time-series, sets and tables. Here we treat multi-modality basically as multimedia, like image, audio and video.
General methods
ReAct (Yao et al., 2023b) integrates dynamic rea- soning with high-level plans for task-specific ac- tions, with feedback from LM and external sources.
Tree of Thoughts (ToT) (Yao et al., 2023a) builds a tree and an evaluation function with an LM to ex- plore multiple different multi-step scenarios, look ahead and backtrack with search algorithms like breadth first search (BFS) and depth first search (DFS). Reasoning via Planning (RAP) (Hao et al., 2023) follow a similar vein and study planning methods like Monto Carlo Tree Search (MCTS).
AdaPlanner (Sun et al., 2023a) is a planning method with an LM for both planning and refining, together with a skill memory.
Wong et al. (2023) propose a probabilistic language of thought (PLoT) for rational meaning construction to integrate neural models of language with probabilistic models for rational inference.
See more work, e.g., Self-Refine (Madaan et al., 2023), RCI (Kim et al., 2023), Reflexion (Shinn et al., 2023), DEPS (Wang et al., 2023d). See also Auto-GPT and BabyAGI.
Games
Games to AI is like fruit flies to genetics. Games AI, in particularly with RL, is promising to push LMs and AI further.
Fan et al. (2022) propose MINEDOJO, an open-ended task suite based on Minecraft game with Internet-scale domain knowledge, together with an agent learning algorithm with large pre-trained models. Voyager (Wang et al., 2023a) explores Minecraft continuously with the modules of automatic curriculum, skill library and iterative prompting mechanism. Plan4MC (Yuan et al., 2023) improves skill learning and planning for Minecraft tasks with assistance from LM.
See Cicero (Bakhtin et al., 2022) in next section. See also Generative Agents (Park et al., 2023) and CAMEL (Li et al., 2023a).
Programming language
Programming language is more formal and thus relatively easier than natural language. Moreover, we may utilize a program interpreter to help judge the correctness and quality of generated codes.
Zhang et al. (2023c) propose Planning-Guided Transformer Decoding (PG-TD) to integrate a planning algorithm like Monte Carlo tree search (MCTS) and the Transformer of an LM to improve the correctness of generated code.
Chen et al. (2023c) propose Self-Debugging to teach an LM to debug generated code via few-shot prompting by identifying mistakes from explanations in natural language, without feedback for code correctness or error messages.
Cai et al. (2023) propose LATM to create reusable tools (Python utility functions) with LMs for both tool making and tool using.
Yang et al. (2023c) propose InterCode, an RL environment for interactive code generation, where observations are execution feedback, actions are code and rewards are either a binary completion score or more complex criteria defined by users.
See early discussion for AdaPlanner (Sun et al., 2023a) and PLoT (Wong et al., 2023) and later for Code as Policies (Liang et al., 2023a) in this section. See Section 6 for CodeRL (Le et al., 2022) and Haluptzok et al. (2023).
Robotics
Robotics come with multi-modality, embodiments and interaction, with perception and action.
There are a series of efforts for robotics: Robotics Transformer (RT-1) (Brohan et al., 2022) for real-world robotics control at scale, Inner Monologue (Huang et al., 2022b) for chaining together perception models, robotic skills, and human feedback for processing and planning in robotic control, SayCan (Ahn et al., 2022) for grounding LM in robotic affordances, ROSIE (Yu et al., 2023) for scaling robot learning with semantically imagined experience, Code as Policies (Liang et al., 2023a) for leveraging LMs to generate policy code for embodied control, and ProgPrompt (Singh et al., 2023) for generating plans with LMs. See RoboCat (Bousmalis et al., 2023) in next section.
3.5 Close-loop feedback with iterative improvements of LMs
As discussed in the last section, most methods with a close-loop feedback share a common feature of self-reference to fixed LMs, which raises the con- cern of how to handle mistakes by LMs. Incorporating multimodality, embodiment and interaction information can help improve grounding and mitigate the issue. Ideally, we can make iterative improvements of LMs from feedback.
Most existing methods focus on feasibility and correctness, rather than optimality. There are emerging works to take one step further by refining LMs with iterative improvements from feedback. See Table 6 for a brief comparison.

Cicero (Bakhtin et al., 2022) integrates an LM with planning and RL algorithms in the seven- player game of Diplomacy to infer players’ beliefs and intentions from conversations and to generate dialogues for negotiation and tactical coordination.
CodeRL Le et al. (2022) follows an actor-critic RL approach during training, with an actor LM for code generation and a critic network for error prediction of generated code as feedback to the actor. During inference, CodeRL leverages unit tests to further improve code generation.
Haluptzok et al. (2023) propose to synthesize programming puzzles and solutions verified by ex- ecution and improve code generation by self-play.
Yang et al. (2023d) propose LeanDojo: an open-source Lean (https://leanprover.github.io) playground with toolkits, data, mod- els, and benchmarks for theorem proving, together with ReProver, a retrieval-augmented prover LM based on a T5-like encoder-decoder Transformer.
Snell et al. (2023) propose implicit language Q-learning (ILQL) to fine-tune an LM to maximize user-specified utility functions.
Carta et al. (2023) propose GLAM to improve functional grounding in interactive environments with RL using an LM as a policy.
RoboCat (Bousmalis et al., 2023) is a visual goal- conditioned foundation model for robotic manipulation, with zero-shot and few-shot generalization, based on Gato (Reed et al., 2022).
Levine (2023b) discusses the purpose of an LM beyond predicting next token and how RL can help fulfill it. Levine (2023a) discusses when data and optimization collaborate, we can solve problems in new ways and in real world outside of simulators.
Yang et al. (2023e) show that foundation models are helpful for all components in decision making: states, actions, rewards, transition dynamics, agents, environments, and applications, with generative modeling or representation learning, thus they will benefit mutually from each other.
RLHF is one application of RL for LMs to handle human value alignment. The discussion above shows that RL may advance LMs in many ways.
3.6 Augmented LMs with tools
A natural way to harnesses the language competence of LMs is by utilizing tools like a search engine, a vector database, a code interpreter, or a symbolic AI solver to handle tasks. A common approach is: 1) converts the natural language description of the problem into the language by the tool, 2) the tool solves the problem, and 3) trans- lates the solution back into text. Table 7 shows a brief comparison.

A method needs to answer questions like which tools/APIs to call, when to call, with what argu- ments, and how to translate the results back into LMs. Toolformer (Schick et al., 2023) and Ge et al. (2023) follows a self-supervised and an RL approach, respectively. HuggingGPT (Shen et al., 2023) relies on an LM.
Demonstrate-Search-Predict (DSP) expresses high-level programs for demonstrations aware of the LM and the retrieval model, relevant passages searches and grounded predictions generation for the LM and the retrieval model to process more re- liably (Khattab et al., 2023), and shows task-aware are favourable to task-agnostic strategies.
Program-Aided Language models (PAL) (Gao et al., 2022) converts a relevant piece of text to code and uses a runtime like a Python interpreter to solve the problem.
LLM+P (Liu et al., 2023a) converts a language description of a planning problem into the planning domain definition language (PDDL), solves it with classical planners, and translates the solution back into text.
See also LangChain, Visual ChatGPT (Wu et al., 2023a), TaskMatrix.AI (Liang et al., 2023c), RCI (Kim et al., 2023), etc.
Domain expertise is still required, see e.g., ChemCrow (Bran et al., 2023). See Mialon et al. (2023) for a survey about augmented LMs. APIBank (Li et al., 2023c) is a benchmark for augmented LMs with tools.
HuggingGPT follows an open-loop without learning from feedback. Toolformer, LLM+P and PAL have feedback during training, but not during inference. DSP and Code as Policies incorporate feedback for improvements, with fixed LMs. Re- Prover incorporates feedback to improve the LM.
4. LMs are approximations
A model specifies how an agent interacts with an environment. A model refers to the transition probability and the reward function, mapping states and actions to distributions over next states and expected rewards, respectively. The agency requires both state and reward prediction, so do LMs. Andreas (2022) admits that, besides predicting text, an agent is what we want for human language technologies, with beliefs and goal achieving.
A model may be built with prior knowledge, from a dataset by estimating parameters, and/or by a generative approach. A simulator may be built based on a model explicitly, e.g., from game rules like the Arcade Learning Environment for Atari games (Bellemare et al., 2013; Machado et al., 2018) or computer Go, chess and shogi (Silver et al., 2018), and physics like Mujoco (Todorov et al., 2012), or implicitly, e.g. those with gen- erative models (Ho and Ermon, 2016; Chen et al., 2019). Planning works with a model or a simulator.
Andreas (2022) emphasizes that current LMs are approximations. Moreover, degrees of approximations should vary for different tasks. It is desirable to characterize such approximation errors.
There are many concrete examples. Kocon ́ et al. (2023) shows that ChatGPT is Jack of all trades, master of none. Valmeekam et al. (2023) shows only 3% success rate of executable plans generated by GPT-3. Li et al. (2023b) shows that OthelloGPT struggles with generating legal moves for the game Othello. Yao et al. (2023a) propose Tree of Thought, and experiments show that GPT-4 can not fully solve the Game of 24.
Errors occur naturally from an approximate model. Compounding errors are particularly serious for sequential decision makings, like a sequence of tokens. When applying an LM in practice, we need to handle errors. One question for practitioners is if it is always feasible to fix an error from a strong LM.
4.1 AlphaGo vs ChatGPT
Next we discuss if LMs may borrow ideas from AlphaGo series, which set a landmark in AI by tackling a very hard problem pursued by many researchers for decades.
The lessons from AlphaGo series follow. 1) With a game rule, there is a perfect model, which can generate infinite high quality data, esp., reliable feedback. 2) This supports iterative improvements of the policy, with trial and error, using general policy iteration, by self play, to achieve a strong computer program. 3) Imitation learning is not enough: In and before AlphaGo, studies use expert games for training. However, self play RL achieves super-human performance in Go, chess, and shogi from scratch, without human knowledge, and also in many other games.
Moreover, Levine (2023a) illustrates that RL can stitch parts of policies to attain a better pol- icy. Levine (2023b) shows that in a tech support application, RL can learn from several specialists for different aspects to improve the job.
For LMs, there is no perfect rule for most problems, neither perfect feedback. Games and code generation appear as exceptions to some extent, with reliable feedback from a game engine and a code interpreter, respectively. The approach in ChatGPT can be treated as imitation learning.
4.2 Bridge LM-to-real gap
An LM like GPT-4 is used as a simulator of the underlaying model in many cases like SELF- INSTRUCT (Wang et al., 2023b) and React (Yao et al., 2023b). However, a simulator usually can not precisely reflect the reality. Also, from the discussion above, LMs are approximations. Then there is a language model to reality gap, or LM-to-real / LM2real gap for short. How to bridge such a gap is critical and challenging.
In applications with physical systems like robotics and autonomous driving, where it is much easier to train an agent in simulation than in reality, simulation to reality gap, or sim-to-real, or sim2real, or reality gap, attract much attention recently. Some LM applications may tolerate more errors, like a writing aid; however, some may be high-stake and/or involve physical systems, e.g., healthcare like Med-PaLM 2 (Singhal et al., 2023) and robotics like SayCan (Ahn et al., 2022).
LMs may borrow ideas from similar study in robotics to reduce the LM-to-real gap. Here is a brief discussion. Chebotar et al. (2019) study how to adapt simulation randomization with real world experience. James et al. (2019) propose to adapt from randomized to canonical scenes, without real-world data. James et al. (2020) propose RLBench, a robot learning benchmark and environment. Deitke et al. (2020) propose RoboTHOR, an open sim-to-real embodied AI platform. Gondal et al. (2019) propose a distanglement dataset to study the sim-to-real transfer of inductive bias. Hanna et al. (2021) study sim-to-real RL with grounded action transformation. Kadian et al. (2020) develop a library Habitat-PyRobot Bridge (HaPy) to execute identical code in simulation and on real robots seamlessly, and investigate sim2real predictivity with a new performance metric Sim-vs-Real Correlation Coefficient. Zhao et al. (2020) present a brief survey on sim-to-real in deep RL for robotics. Lavin et al. (2021) discuss simulation intelligence.
5. Iterative improvements from feedback
Iterative improvements from feedback provides a general approach to achieving optimality and improving adaptability of LMs. It makes the foundation sound and solid, by improving the world model, improving grounding for better understanding and better consistency with the world, and improving agency for goal achieving.
Figure 3 illustrates the framework of iterative improvements from feedback with modularity in a general sense. Modules 0-N send decisions to and receive feedback from other modules, tools, APIs, and the task. Module 0 serves as a coordinator. Modules can interact and learn from each other. Tools and APIs can be regarded as fixed modules; i.e., they do not learn. One or more of Modules 1-N may be large LMs, and keep fixed, i.e., not learn from feedback. From RL’s perspective, a learning module is an agent, and the rest is its environment.
Such a framework is general. We focus on LMs here. The prohibitive cost of updating large LMs will not allow for relatively frequent iterative improvements from feedback. As a result, next generation LM systems would follow a modular architecture, potentially with many small LMs, rather than a monolithic, general-purpose large LM.
There will be many modules with specific expertise, for horizontal functionalities and vertical applications. In particular, one module serves as the interface to users and coordinates all LMs, tools, and APIs. Another module builds the world model from interactions with the world. Moreover, one or more module are dedicated to safety and ethics.
We may deploy one or a couple of large LMs to harness the language competence and functionalities large LMs outperform small LMs significantly. Large LMs are kept fixed, to avoid prohibitive up- dating costs and/or due to their being proprietary, until when new versions are available. Small LMs can improve iteratively from feedback, from users, other LMs, tools, APIs, and all the rest of the world, using reinforcement learning and AI algorithms. Small LMs are preferred to large LMs, esp. when small LMs are good enough.
Modularity with small models is promising for further progress in AI. Augmenting LMs with tools, APIs and plugins is an evidence for modularity. It also becomes feasible for players without huge resources, thus more amenable for AI academics (Togelius and Yannakakis, 2023).
5.1 Connection with existing methods
Pre-training then fine-tuning is common for LMs. As discussed in Section 3, most approaches improve prompts with fixed LMs, like GPT-4.
ChatGPT follows iterative deployment (OpenAI, 2022a,b), making updates after collecting a big batch of users’ feedback. This may be the edge GPT-4 over other large LMs. This is helpful for making improvements. It is reasonable since a huge LM is too costly to update often. However, it is desirable to make more frequent refinements.
It is feasible to fine-tune a small LM frequently, or even to incorporate feedback when building it.
Prompting provides the initial condition of a lan- guage model, or the starting “previous tokens” in ChatGPT. It is desirable to leverage mature tools. Prompting and augmentation with tools depend on the capability of an LM, need to handle errors, and are not able to improve an LM.
Consider LM as a policy, supervised fine-tuning, parameter efficient fine-tuning and reinforcement learning from human feedback follow the approach of imitation learning. As discussed in Section 4.1, imitation learning is not enough. RL is thus promising for LMs.
5.2 Experience and model
Sutton (2022a) talks about the increasing role of sensorimotor experience in AI to be more grounded, learnable and scalable. Sensorimotor experience is the sensations and actions of an agent’s ordinary interaction with the world.
Sutton (2022b) proposes the common model of intelligent agent, which is model-based RL. It integrates experience with model, aligning with Pearl (2020). It reconciles nature with nurture, empiricism with rationalism, and connectionism with symbolism. The common model is thus promising for achieving sound and solid grounding and agency. The common mode is conceptually similar to the autonomous machine intelligence architecture (LeCun, 2022), which includes configurator, perception, world model, actor, critic, intrinsic cost, and short term memory. Mialon et al. (2023) discuss a modular implementation, which applies similarly to the common model. See Section 6.6 for more discussion about general intelligence.
Building on trial and error with experience, close-loop optimal control with dynamic programming, and temporal difference learning (Sutton and Barto, 2018), reinforcement learning naturally implements iterative improvements from feedback.
6. Challenges and opportunities
We discuss challenges and opportunities to implement iterative improvements from feedback, in particular, data, feedback, methodology, evaluation, interpretability, constraints and intelligence.
6.1 Data and feedback
The importance of training data are second to none for big data problems, like many with deep learning, specifically, LMs. It is critical to follow the princi- ple pf ground-truth-in-the-loop. Recent success of LMs, among many machine learning applications, provides evidence.
Olausson et al. (2023) show the importance of feedback from tests and human programmers for repairing code generated by LMs. phi-1 (Gunasekar et al., 2023) shows the importance of high-quality textbook-like data. LIMA (Zhou et al., 2023a) shows the importance of high-quality of instruc- tion data.
Shumailov et al. (2023) discuss the issue of model collapse due to training with generated data from LMs as well as Gaussian Mixture Models (GMMs) and Variational Autoencoders (VAE), and show the importance of genuine human data for LMs. Alemohammad et al. (2023) show the Model Autophagy Disorder (MAD), where quality (precision) and diversity (recall) of generative models decrease progressively in generations of an autophagous (self-consuming) loop without sufficient new real data. Gudibande et al. (2023) show the issue of imitating large LMs. This explicitly indicates issues with methods generating data from LMs like SELF-INSTRUCT (Wang et al., 2023b). It also casts doubts on many self-reference methods, like most of those discussed in Section 3, namely, those rely on feedback from fixed LMs.
Feedback is indispensable for an iterative approach. In RL, rewards provide evaluative feedback for agents to make decisions. We discuss feedback in the context of LMs in Section 3. Here we discuss reward, interaction, as well as their connection with psychology, which will shed light on iterative improvements of LMs with feedback. Feedback is also data. We single it out here from data to highlight the nature of interaction.
Sparse reward
Rewards may be so sparse that it is challenging for learning algorithms, e.g., in text generation with RLHF, a reward may occur at the completion of the text. Lightman et al. (2023) propose process supervision rather than output supervision to have denser feedback. Hindsight Experience Replay (HER) (Andrychowicz et al., 2017) is a way to han- dle sparse rewards. Unsupervised auxiliary learning (Jaderberg et al., 2017) is an unsupervised way harnessing environmental signals. Intrinsic moti- vation (Barto, 2013; Singh et al., 2010) is a way to provide intrinsic rewards. Colas et al. (2020) present a short survey for intrinsically motivated goal-conditioned RL.
Reward shaping is to modify reward function to facilitate learning while maintaining optimal policy (Ng et al., 2000). It is usually a manual endeavour. Jaderberg et al. (2018) employ a learning approach in an end-to-end training pipeline.
Imitation learning
Reward functions may not be available for some RL problems. In imitation learning (Osa et al., 2018), an agent learns to perform a task from expert demonstrations, with sample trajectories, with- out reinforcement signals. Two main approaches are behavioral cloning and inverse RL. Behavioral cloning, or learning from demonstration, maps state-action pairs from expert trajectories to a pol- icy, maybe as supervised learning, without learning the reward function (Levine, 2021). Inverse RL is determines a reward function given observations of optimal behavior (Ng and Russell, 2000). Probabilistic approaches are developed for inverse RL with maximum entropy (Ziebart et al., 2008) to deal with uncertainty in noisy and imperfect demonstrations. Ross et al. (2010) reduce imitation learning and structured prediction to no-regret online learning, and propose Dataset Aggregation (DAGGER), which requires interaction with the expert. Abbeel and Ng (2004) approach apprenticeship learning via IRL. Syed and Schapire (2007), Syed et al. (2008), and Syed and Schapire (2010) study apprenticeship learning with linear programming, game theory and reduction to classification.
Supervised fine-tuning follows a behavioral cloning approach. RLHF follows an inverse RL approach. Both of them follow imitation learning.
Reward function
A reward function may not represent the intention of the designer. A negative side effect of a misspecified reward refers to potential poor behaviors resulting from missing important aspects. An old example is about the wish of King Midas, that everything he touched, turned into gold. Unfortunately, his intention did not include food, family members, and many more. Russell and Norvig (2020) give an example that a vacuum cleaner collects more dust to receive more rewards by ejecting collected dust. Hadfield-Menell et al. (2016) propose a cooperative inverse RL (CIRL) game for the value alignment problem. Hadfield-Menell et al. (2017) introduce inverse reward design (IRD) to infer the true reward function, based on a designed reward function, an intended decision problem, e.g., an MDP, and a set of possible reward functions. Dragan (2020) talks about optimizing intended reward functions.
Embodiments and social interaction
As discussed in Section 2.1, LMs can interact with physical and human worlds through embodiments and social interaction to improve grounding and agency. Shumailov et al. (2023) discuss the model collapse issue when sampling from a learned model like an LM. Iterative improvements from feedback by interacting with the world, like the Dyna framework (Sutton and Barto, 2018), can mitigate or even eliminate such an issue.
Liu et al. (2023d) propose Sirius for human-in-the-loop learning for robotics. As discussed earlier, Lee et al. (2021) propose PEBBLE leveraging human-in-the-loop feedback. Before the large language model era, Abbeel (2021) discusses that, similar to the pre-training then finetuning in computer vision on ImageNet and in NLP, like GPT-X and BERT, on Internet text, we may be able to pre-train large-scale neural networks for robotics as a general solution, with unsupervised representation learning on Internet video and text, with un-supervised (reward-free) RL pre-training, mostly on simulators and little on the real world data, with human-in-the-loop RL, and with few shot imitation learning on demonstrations.
Reinforcement learning integrates with social learning, e.g., Krishna et al. (2022) show that socially situated AI helps learning from human interaction, and Ndousse et al. (2021) study social learning via multi-agent RL. Wang et al. (2023c) survey interactive NLP, considering interactions with humans, knowledge bases (KBs), models and tools, and environments. In Figure 3, users together with tools and APIs including KBs and models are part of the environment. Bolotta and Dumas (2022) discuss social interaction as the “dark matter” of AI.
Connection with psychology
When humans are involved, psychology and be- havioural science may provide insights. From self-motivation theory (Ryan and Deci, 2020), the basic psychological needs of autonomy, competence and relatedness mediate positive user experience out- comes such as engagement, motivation and thriving (Peters et al., 2018). Flow is about the psychology of optimal experience (Csikszentmihalyi, 2008). As such, they constitute specific measurable parameters for which designers can design in order to foster these outcomes within different spheres of experience. Such self-motivation theory and flow, or positive psychology, may help the design of reward and human-computer interaction (HCI), and there are applications in games (Tyack and Mekler, 2020), education (Ryan and Deci, 2020), etc. Cruz and Igarashi (2020) survey design principles for interactive RL. Intrinsic motivation has been applied in RL as discussed earlier. RLHF is an approach dealing with preference and value alignment. However, it appears that self-motivation theory, flow and positive psychology are under-explored in AI.
6.2 Methodology
AI, in particular, LMs, is enjoy a rapid progress. With ample resources including talents, compute and fundings and the focused attention, there will be more efficient and effective solutions from hardware to software, from theory to practice, including but not limited to processor, system level softwares like compilers and schedulers, neural network architecture, learning algorithms like those for pre-training and fine-tuning, distributed and/or decentralized algorithms, all sorts of applications ranging from enterprise to customer and from cloud to edge devices, and solving issues like hallucination, privacy, safety and human-value alignment.
See Tay et al. (2022) for a survey about efficient Transformers. See Treviso et al. (2023) for a survey about efficient methods for NLP.
For concrete examples, see e.g., Backpack (Hewitt et al., 2023) for a new network architecture, RWKV (Peng et al., 2023) for reinvention of RNN for LMs, Sophia (Liu et al., 2023c) a second-order optimizer for speed-up, AWQ (Lin et al., 2023) for compression and acceleration, and Goat (Liu and Low, 2023) outperforming GPT-4 on arithmetic tasks. We introduce Gorilla (Patil et al., 2023), TinyStories (Eldan and Li, 2023) and phi- 1 (Gunasekar et al., 2023) in Section 2.6. See a talk (Choi, 2022) about small vs large LMs.
Ramamurthy et al. (2023) propose an open-source modular library, Reinforcement Learning for Language Models (RL4LMs), General Reinforced-language Understanding Evaluation (GRUE) benchmark, and an RL algorithm Natural Language Policy Optimization (NLPO).
Sutton (2019) states that search and learning are general purpose methods that scale arbitrarily with computation, and also highlights the importance of meta methods. People may tend to scale up the sizes of the neural network and the training dataset to achieve better performance, refering to the Bitter Lesson as a support, which, however, is a mis-reading. For example, scaling up heuristic search algorithms like A* and IDA* failed to achieve a superhuman Go. AlphaGo resulted from the culmination of achievements in deep learning, reinforcement learning, and Monte-Carlo tree search (MCTS), together with powerful computing. See also Brooks (2019); Kaelbling (2019).
Deshpande et al. (2023) study downscaling ef-fects with a shrunk language, showing benefits of pre-training models of 1.25M parameters and that compute-optimal models break the power law. McKenzie et al. (2023) provide 11 datasets for empirical analysis of inverse scaling laws and discuss the importance of data and objectives for training LMs. Zhang et al. (2023e) propose NeQA, a dataset containing questions with negation and exhibit inverse, U-shaped, or positive scaling. For a “historical” context, Kaplan et al. (2020) study scaling laws that the overall cross-entropy loss of an LM improves with the increased scale of model, dataset and compute for training, and Hoffmann et al. (2022) show that the model and data should be scaled equally for compute-optimal training.
Consider the journey from ENIAC in 1945, 27 tons, equivalent to US$6,200,000 in 2021 to iPhone in 2007, 3.5 inch, 135g, 600+ MHz CPU, GPU, 128MB eDRAM, 16GB flash memory, US$499. with faster iterations, we expect smaller, cheaper, yet more capable LMs to appear soon.
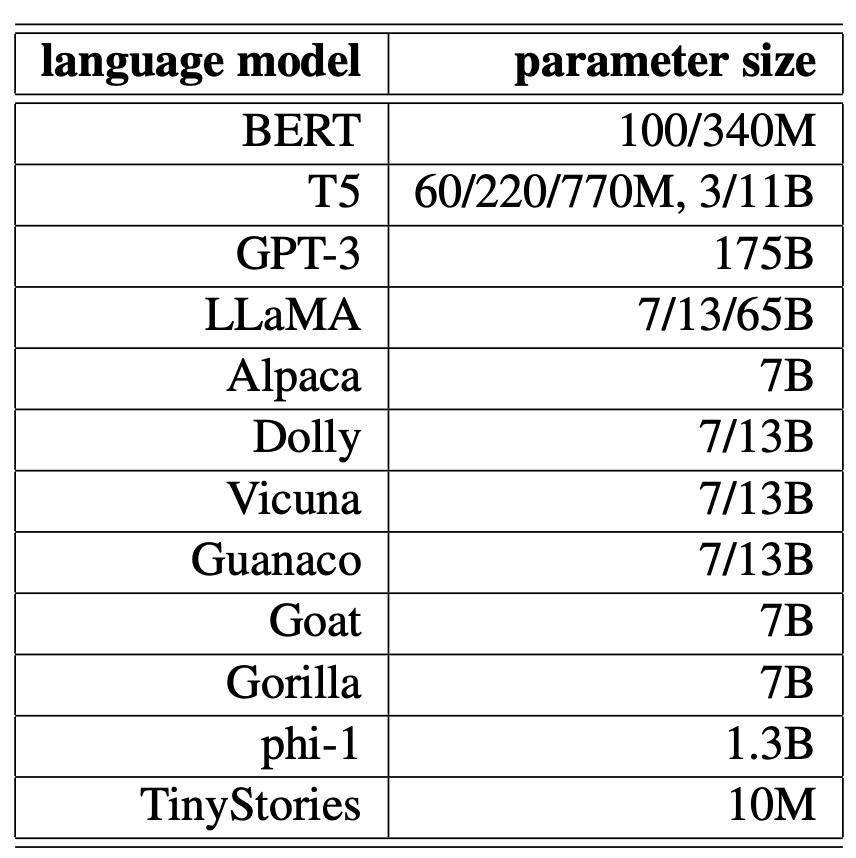
Table 8 shows a glimpse of LM parameter sizes.
6.3 Evaluation
Evaluation provides feedback to researchers and developers, as well as to learning algorithms, to make improvements. Evaluation and benchmarks for NLP and language models have been making steady progress. However, there are still lots of challenges, in particular, for interactive applications. See Chang et al. (2023) for a survey.
Burnell et al. (2023) presents guidelines for robust evaluation practices with more granular re- porting, in particular, in-depth performance break-downs beyond aggregate metrics and instance-by-instance evaluation results.
Gehrmann et al. (2022) survey obstacles in evaluation of test generation and propose to evaluate a model with multiple datasets via multiple metrics and document human evaluation well. The authors propose the following best best practice & implementation: make informed evaluation choices and document them, measure specific generation effects, analyze and address issues in the used dataset(s), evaluate in a comparable setting, run a well-documented human evaluation, produce ro- bust human evaluation results, document results in model cards, and release model outputs and anno- tations.
Srivastava et al. (2022) introduce the Beyond the Imitation Game benchmark (BIG-bench) which has more than 200 tasks.
Liang et al. (2022) present HELM, Holistic Evaluation of Language Models, to improve trans- parency of LMs. The authors present a taxonomy of scenarios and metrics to evaluation LMs with a multi-metric approach: a) evaluate 16 core sce-narios each with 7 metrics, namely, accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency; b) conduct 7 targeted evaluations for 26 targeted scenarios for specific aspects like knowledge, reasoning, memorization, copyright and disinformation; and c) evaluate 30 LMs on all 42 scenarios.
Lee et al. (2022) introduce Human-AI Language-based Interaction Evaluation (HALIE) to extend non-interactive evaluation w.r.t three factors: 1) targets, including full process and final output, 2) perspectives, including first-person and third-party, and 3) criteria including preference and quality.
Biderman et al. (2023) propose Pythia to study the process of training LMs with checkpoints for 16 LMs with parameter sizes from 70M to 12B.
Maynez et al. (2023) benchmark LM capacities for 27 generation tasks and provide recommenda- tions on the selection of tasks, methods and metrics, and on practice to monitor generation capacities including benchmarks, automated metrics, and efficient utilization of computational resources.
Mozannar et al. (2023) propose CodeRec User Programming States (CUPS) to model user behaviour and costs in AI-assisted programming with GitHub Copilot and show that 34.3% of total session time spends on double-checking and editing suggestions.
Francis et al. (2023) discuss the principles for social robot navigation: safety, comfort, legibility, politeness, social competency, agent understanding, proactivity and responsiveness to context, and based on which, the guidelines for evaluation w.r.t. metrics, scenarios, benchmarks, datasets and simulators.
6.4 Interpretability
Explainability and interpretability are critical for AI (Barredo Arrieta et al., 2020). We briefly re- view some work and make connection with many concepts/issues in AI.
First we discuss the definition. As in Rudin et al. (2021), explainable AI (XAI) “attempts to explain a black box using an approximation model, derivatives, variable importance measures, or other statistics”, whereas interpretable ML creates “a predictive model that is not a black box”. In Murdoch et al. (2019), interpretable ML includes explainable ML, intelligible ML, and transparent ML. Lipton (2018) argues that explanation is post hoc interpretability. Miller (2019) treats explainability and interpretability as the same.
Miller (2019) survey how people define, gener- ate, select, evaluate, and present explanations in philosophy, psychology, and cognitive science and the implication for explainable AI. The major findings are: explanations are contrastive, explanation are selected in a biased manner, probabilities probably don’t matter, and explanations are social. The author summarized that “explanations are not just the presentation of associations and causes (causal attribution), they are contextual”.
Doshi-Velez and Kim (2017) propose to define interpretability “as the ability to explain or to present in understandable terms to a human”. The authors discuss the relationship between interpretability with other desiderata of ML systems. Fairness or unbiasedness concerns with groups being protected from explicit or implicit discrimination. Privacy is about the protection of sensitive information in the data. An algorithm is reliable and robust if it can achieve a certain level of performance with variation in parameters or inputs. The predicted change in output due to a perturbation, according to causality, will occur in the real system. A method is usable if it provides information to help users to accomplish a task. Trust is about a system with confidence of human users. Interpretability qualitatively assists to meet these properties: fairness, privacy, reliability, robustness, causality, usability and trust.
Lipton (2018) discusses the desiderata and methods for interpretable AI. Desiderata include trust, causality, transferability, informativeness, and fair and ethical decision making. Techniques and model properties for interpretability include trans- parency and post hoc explanations. The different levels of transparency are: simulatability for the entire model, decomposability for individual components such as parameters, and algorithmic transparency for the training algorithm.
Murdoch et al. (2019) propose to define interpretable machine learning as “the extraction of relevant knowledge from a machine-learning model concerning relationships either contained in data or learned by the model”. The authors propose the predictive, descriptive, relevant framework, with desiderata for evaluation: predictive accuracy, descriptive accuracy, and relevancy judged relative to a human audience.
Rudin et al. (2021) propose to define interpretable ML in one sentence: “an interpretable model is constrained, following a domain-specific set of constraints that make reasoning processes understandable”. The authors discusses five principles and ten grand challenges of interpretable ML.
Kim (2023a) proposes to build a language to communicate with AI for alignment with our val- ues, by reflecting the nature of the machines and expanding what we know.
Neural networks are notoriously known as black- boxes, especially giant ones like GPT-3. Bills et al. (2023) propose to explain neurons in LMs with LMs, rather than with ground truths. A local explainable method has inherent limitations since distributed representation is critical for neural networks. Moreover, a local method like saliency maps may have issues, e.g., see Adebayo et al. (2018) and Rudin (2019). Rudin (2019) discusses issues with post hoc explainable methods for high stakes decisions and argues to use inherent interpretable approaches instead. Explainability and interpretability for (large) LMs is still nascent and calls for more investigations.
6.5 Constraints
AI for good is a goal. Besides predictive and optimal, it is desirable for an AI system to be safe, robust, adaptive, reliable, stable, transparent, fair, trustworthy, explainable, etc., and not to have behaviours like discrimination w.r.t. race, gender, nationality, etc. Constrains may express them.
A predictive model is built on domain knowledge, real-world data, and high-fidelity simulators; a robust method accounts for worst-case scenarios and takes conservative actions, and an adaptive method learns from online observations and adapts to unknown situations (Brunke et al., 2021).
Thomas et al. (2019) discuss that, to prevent undesirable behaviour of intelligent machines, a user of a standard ML algorithm needs to constrain the algorithm’s behaviour in the objective function (with soft constraints or robust and risk-sensitive methods) or in the feasible set (with hard constraints, chance constraints, or robust optimization methods), both of which requires domain knowledge or extra data analysis. The authors propose a framework to shift the burden from the user to the designer of the algorithm, by allowing the user to place probabilistic constraints on the solution directly, for classification, regression, and RL.
Wiens et al. (2019) discuss how to do no harm in the context of healthcare, which may somewhat generalize to AI. AI practitioners, esp. those with AI power and resources and/or those dealing with high-stake applications like healthcare and au- tonomous driving, may need to take a “Hippocratic oath” or even go under stricter regulation.
Wing (2021) reviews trustworthy AI. Brunke et al. (2021) survey safe learning in robotics, with perspectives from learning-based control to safe RL. Szepesvári (2020) discusses multi-objective and constrained RL. García and Fernández (2015) present a survey on safe RL. It is interesting to explore how to incorporate ideas about constraints to LMs.
6.6 Intelligence
There are long-standing debates about nature versus nurture, empiricism versus rationalism, and connectionism vs symbolism. We discuss earlier the importance of experience (Sutton, 2022a), a common model of intelligent agent (Sutton, 2022b), an autonomous machine intelligence architecture (LeCun, 2022), and a modular architecture Mahowald et al. (2023).
Lake et al. (2017) discuss that we should build machines toward human-like learning and thinking. In particular, we should 1) build causal world models to support understanding and explanation, seeing entities rather than just raw inputs or features, rather than just pattern recognition, 2) support and enrich the learned knowledge grounding in intuitive physics and intuitive psychology, and 3) represent, acquire, and generalize knowledge, leveraging compositionality and learning to learn, rapidly adapt to new tasks and scenarios, recombining representations, without retraining from scratch.
Jordan (2019) highlights the need of meaning and reasoning for NLP, causality, representations of uncertainty and long-term goals.
Pearl (2020) discusses that learning is guided by data and model, and argues the importance of balancing empiricism with a model for expediency, transparency and explainability.
Bengio et al. (2021) propose a neuro-symbolic approach to combine the merits from both sides: symbolic AI for system 2 abilities like reasoning, composability, and abstraction, and strengths of deep learning including “efficient large-scale learn- ing using differentiable computation and gradient-based adaptation, grounding of high-level concepts in low-level perception and action, handling uncertain data, and using distributed representations”. Littman et al. (2021) also highlights a neuro-symbolic approach.
Legg and Hutter (2007) compare tests of intelligence w.r.t. the following properties: valid, informative, wide range, general, dynamic, unbiased, fundamental, formal, objective, fully defined, universal, practical, and test vs. definition. Chollet (2019) presents the Abstraction and Reasoning Corpus (ARC) benchmark.
Learning to learn is a core ingredient to achieve strong AI (Botvinick et al., 2019; Kaelbling, 2020; Lake et al., 2017; Sutton, 2019), and has a long history, e.g., Schmidhuber (1987), Bengio et al. (1991), and Thrun and Pratt (1998).
Learning to learn, a.k.a. meta-learning, is learning about some aspects of learning. It includes concepts as broad as transfer learning, multi-task learning, one/few/zero-shot learning, learning to reinforcement learn, learning to optimize, learn- ing combinatorial optimization, hyper-parameter learning, neural architecture design, automated machine learning (AutoML)/AutoRL/AutoAI, etc. It is closely related to continual learning and life-long learning (Khetarpal et al., 2020).
The aim of few-shot meta-learning is to train a model adaptive to a new task quickly, using only a few data samples and training iterations (Finn et al., 2017). Transfer learning is about transfer-ring knowledge learned from different domains, possibly with different feature spaces and/or different data distributions (Taylor and Stone, 2009; Pan and Yang, 2010). Curriculum learning (Bengio et al., 2009; Narvekar et al., 2020; Baker et al., 2020; Vinyals et al., 2019), model distillation/compression (Hinton et al., 2014; Czarnecki et al., 2019), and sim-to-real are particular types of transfer learning. Multitask learning (Caruana, 1997) learns related tasks with a shared representation in parallel, leveraging information in related tasks as an inductive bias, to improve generalization, and to help improve learning for all tasks. Schölkopf et al. (2021) discuss causal representation learning for transfer learning, multitask learn- ing, continual learning, RL, etc. SeeHutter et al. (2019) for a book on AutoML, Hospedales et al. (2021) for a survey on meta-learning, Singh (2017) for a tutorial about continual learning, (Chen et al., 2021) for a survey and a benchmark on learn to optimize, and (Portelas et al., 2020) for a survey on automatic curriculum learning for deep RL.
The above sheds lights on how to achieve more general and stronger intelligence.
Gershman et al. (2005) discuss that computational rationality leads to approximations when maximizing expected utility for decision making, considering the cost of computation in complicated real-world problems. Although there is exponentially growth in computation, this is (very likely) still a valid principle.
Learning to learn, like transfer / few-shot / multi- task / meta-learning are popular methods for general intelligence recently. General intelligence thus boils down to multi-objective and/or multi- constraint problems, which are about approxima- tion and compromise. See Section 4 for approximation and Section 6.5 for constraints.
When building an AI system, we need to consider the boundary and set a pragmatical goal. Instead of training a system optimizing everything or handling all potential tasks satisfactorily, we may follow how humans have been organizing the society in the long history, i.e., decompose the whole into parts, solve them separately and let them collaborate. In the pre-training then fine-tuning pipeline, we may pre-train with data from selected rather than all sorts of tasks to improve the quality of representation (Schölkopf et al., 2021) and to avoid issues like negative transfer (Taylor and Stone, 2009; Pan and Yang, 2010).
7. Conclusion
Iterative improvements from feedback is a general approach for many, if not all, successful systems. Ground-truth-in-the-loop is critical. Reinforcement learning is a promising framework to achieve sound and solid grounding and agency of language mod- els, by interacting with physical and social world, although pre-training then fine-tuning is a popular approach. Small modules are feasible for frequent updates. This helps bridge the LM-to-real gap and achieve optimality and controllability, besides feasibility and correctness. This facilitates adaptability of language models to humans, but not vice versa, as current prompt engineering may require significant efforts for humans to adapt to language models. This requires valuable and reliable data, feedback and evaluation, with sample-, time-, and space-efficient algorithms, considering ethical and social issues.
Limitations
This is a perspective paper with a brief survey. More considerations are needed for ethical and social aspects of language models and AI.
References
See the PDF file. Iterative improvements from feedback for language models