
Reinforcement learning is all you need, for next generation language models.
Iterative improvements from feedback. Interact with the world; perceive the world; transform the world. Grounding and agency. Reinforcement learning is the natural and right framework.

AlphaGo and ChatGPT are two most influential AI achievements recently. AlphaGo and its sequels AlphaGo Zero and AlphaZero are based on deep learning, reinforcement learning (RL), Monte Carlo tree search (MCTS), and self play. ChatGPT and GPT-n and many large language model (LLM) variants are based on deep learning, in particular, Generative AI, Pre-trained models, and self-attention Transformers.
AlphaZero has achieved super-human performance in Go, chess and shogi. LLMs are fascinating, yet still facing issues like hallucination, misinformation, and lacking of planning and reasoning. See e.g., the Limitations, Risk & mitigations in the GPT-4 blog and the System Card in the GPT-4 Technical Report.
Such issues, like factuality, may appear simple. However, no LLM can handle them well yet. Moravec’s Paradox resonates. Similarly, Steven Pinker stated in 1994 that “the main lesson of thirty-five years of AI research is that the hard problems are easy and the easy problems are hard.”
Can we leverage AlphaGo, in particular, reinforcement learning, to improve language models? The answer is YES. Here is the explanation.
Executive summary
Self-play reinforcement learning works for games AI, due to perfect game rules.
Current LLMs are not oracle. They make mistakes.
Fully autonomous agents based on LLMs are not ready yet.
RLHF is an appetizer, while RL is the main course.
Grounding and agency are indispensable for a sound and solid language model.
Grounding is about meaning, understanding, and being consistent with the world.
Agency is about learning and decision making to achieve goals.
Imitation learning is not enough.
Contexts: small annotated data, Internet texts, multimodality, embodiment, and social interaction.
Interact with the world, perceive the world, and transform the world.
Iterative improvements from feedback are necessary for language models.
Reinforcement learning is the natural and right framework.
Reinforcement learning: a very brief introduction
An RL agent interacts with the environment over time to learn a policy, by trial and error, that maximizes the long-term, cumulative reward. At each time step, the agent receives an observation, selects an action to be executed in the environment, following a policy, which is the agent’s behaviour, i.e., a mapping from an observation to actions. The environment responds with a scalar reward and by transitioning to a new state according to the environment dynamics. The following figure (from Reinforcement Learning: An Introduction) illustrates the agent-environment interaction.

The figure below illustrates the relationship among reinforcement learning, deep learning, deep reinforcement learning, supervised learning, unsupervised learning, machine learning, and AI. We usually categorize machine learning as supervised learning, unsupervised learning, and reinforcement learning. However, they may overlap with each other. Deep learning can work with/as these and other machine learning approaches. Supervised learning requires labeled data. Unsupervised learning takes advantage of the massive amount of data without labels. Self-supervised learning is a special type of unsupervised learning in which no labels are given; however, labels are created from the data. Auxiliary learning in RL can be regarded as self-supervised learning. Deep reinforcement learning, as the name indicates, is at the intersection of deep learning and reinforcement learning. Deep learning is part of machine learning, which is part of AI. The approaches in machine learning on the left is based on Wikipedia. The approaches in AI on the right is based on Artificial Intelligence: A Modern Approach. Note that all these fields are evolving, e.g., deep learning and reinforcement learning are addressing many classical AI problems, such as logic, reasoning, and knowledge representation.

Reinforcement learning is a general framework for sequential decision making, with broad applications. See Reinforcement Learning: An Introduction, as well as Deep Reinforcement Learning: An Overview, Reinforcement Learning Applications, and Reinforcement Learning in Practice: Opportunities and Challenges for more details.
AlphaGo: a very brief introduction
AlphaGo: Mastering the game of Go with deep neural networks and tree search (the movie) is the first program to defeat a world champion in the game of Go. AlphaGo Zero: Mastering the game of Go without human knowledge achieves superhuman performance in Go, starting tabula rasa. AlphaZero: Mastering Atari, Go, chess and shogi by planning with a learned model defeats a world champion program in the games of chess, shogi, and Go, starting from random play and w/o domain knowledge except game rules.
The discussion is based on AlphaGo Zero, which is an elegant algorithm, and is the base for AlphaZero.
AlphaGo Zero starts from scratch with randomized weights for a neural network to represent the policy and the value function. At each step during a self play, it simulates each move with Monte Carlo tree search (MCTS). At the end of the game, it collects data for this play. It minimizes a loss function including data for both policy and value function to perform both policy evaluation and policy improvement, conducting a step of policy iteration. Gradually, AlphaGo Zero achieves a very strong policy.
The following figure is based on AlphaGo Zero. See Deep Reinforcement Learning: An Overview for more discussion and a pseudocode algorithm.

Experience grounds language
As discussed in the paper Experience Grounds Language (EMNLP 2020), a language describes the physical world and facilitates the social interactions. “You can’t learn language from the radio (Internet).” “You can’t learn language from a television.” “You can’t learn language by yourself.”

The paper presents five World Scopes (WS).
WS1. Corpus (our past). Corpora and Representations. Small scale.
WS2. Internet (most of current NLP). The Written World. Large scale.
WS3. Perception (multimodal NLP). The World of Sights and Sounds.
WS4. Embodiment. Embodiment and Action. Interaction with physical world.
WS5. Social. The Social World. Interaction with human society.

The authors posit that “These World Scopes go beyond text to consider the contextual foundations of language: grounding, embodiment, and social interaction.” Grounding is about meaning and understanding. Embodiment is about interaction, with action, reward and planning, in particular, in a physical world. Social interaction is about communication in human society. Agency is about, with belief, desire and intention, acting to achieve goals. From Reinforcement Learning: An Introduction, “The learner and decision maker is called the agent.”
The authors postulate that “the present success of representation learning approaches trained on large, text-only corpora requires the parallel tradition of research on the broader physical and social context of language to address the deeper questions of communication”, and encourage “the community to lean in to trends prioritizing grounding and agency, and explicitly aim to broaden the corresponding World Scopes available to our models”.
The authors “call for and embrace the incremental, but purposeful, contextualization of language in human experience.” “Computer vision and speech recognition are mature enough for investigation of broader linguistic contexts (WS3).” “The robotics industry is rapidly developing commodity hardware and sophisticated software that both facilitate new research and expect to incorporate language technologies (WS4).” “Simulators and videogames provide potential environments for social language learners (WS5).”
Note that in The Development of Embodied Cognition: Six Lessons from Babies, the embodiment also include social interaction. “The embodiment hypothesis is the idea that intelligence emerges in the interaction of an agent with an environment and as a result of sensorimotor activity.” The six lessons are: Be multimodal, be incremental, by physical, explore, by social, use language. See also From Machine Learning to Robotics: Challenges and Opportunities for Embodied Intelligence.
Language model: a very brief introduction
A language model is about the probability distribution of a sequence of tokens. An auto-regressive language model is about the probability distribution of next token, given previous tokens, i.e., the following conditional probability distribution:
Probability(next token | previous tokens).
We call this a language model, following ChatGPT. For more discussion about language model, see Will AGI Emerge from Large Language Models?
Such a language model can be regarded as a policy, where the “previous tokens” are the state (observation) and the “next token” is the action.
Many problems in natural language process (NLP) are actually sequential decision making problems, thus RL is a natural framework. See, e.g., Deep Reinforcement Learning: An Overview.
ChatGPT and RLHF: a very brief introduction
In the pre-training stage, LLMs, and Foundation models in general, are “trained on broad data (generally using self-supervision at scale) that can be adapted to a wide range of downstream tasks.”
After pre-training, ChatGPT conducts reinforcement learning from human feedback (RLHF) in three steps as in the figure below. Step 1: supervised fine-tuning. Step 2: reward model learning. Step 3: reinforcement learning. See the blog ChatGPT: Optimizing Language Models for Dialogue and the InstructGPT paper: Training language models to follow instructions with human feedback for more details.

As discussed by Yoav Goldberg, a “traditional” language model is trained with natural text data alone, while ChatGPT is not traditional any more: it is augmented with instruction tuning, programming language code data, and reinforcement learning from human feedback.
Later we will argue that RLHF is an appetizer, while RL is the main course.
“Emergent abilities”
The GPT-3 paper Language Models are Few-Shot Learners popularized the concept of in-context learning to use language models to learn tasks with only a few examples. There are more studies, e.g., Emergent Abilities of Large Language Models and Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. However, a tweet shows that “for a given NLP task, it is unwise to extrapolate performance to larger models because emergence can occur.” See also Are Emergent Abilities of Large Language Models a Mirage?
Language vs thought or formal vs functional competence
In Dissociating language and thought in large language models: a cognitive perspective, the authors “review the capabilities of LLMs by considering their performance on two different aspects of language use: ‘formal linguistic competence’, which includes knowledge of rules and patterns of a given language, and ‘functional linguistic competence’, a host of cognitive abilities required for language understanding and use in the real world.” and conclude that “LLMs show impressive (although imperfect) performance on tasks requiring formal linguistic competence, but fail on many tests requiring functional competence.” The authors argue that “(1) contemporary LLMs should be taken seriously as models of formal linguistic skills; (2) models that master real-life language use would need to incorporate or develop not only a core language module, but also multiple non-language-specific cognitive capacities required for modeling thought.” The authors also discuss two fallacies: “good at language -> good at thought” and “bad at thought -> bad at language”.
How to leverage LLMs?
We leverage LLMs’ competence as good models of language. When necessary, we manage to improve the functional competence, e.g., factuality, safety, and reasoning. Prompting can leverage LLMs. Fine-tuning with domain data can improve an LLM for the domain. Integrating LLMs with tools can achieve various functionalities.
There are specialized models like Deepmind AlphaFold, Github Copilot (using OpenAI Codex), Deepmind AlphaCode, Google Robotics Transformer (RT-1), Stanford PubMedGPT 2.7B, Microsoft BioGPT, BloombergGPT, Google Med-PaLM 2, Google MusicLM, AudioGPT.
Following LLaMA (Large Language Model Meta AI), more and more “small” language models appear, like Stanford Alpaca, Databricks Dolly, Berkeley Koala, Vicuna, Stability AI StableLM, NUS ColossalChat.
Consider ENIAC in 1945, 27 tons, equivalent to US$6,200,000 in 2021 and iPhone in 2007, 3.5 inch, 135g, 600+MHz CPU, GPU, 128MB eDRAM, 16GB flash memory, US$499. With faster iterations, we expect smaller, cheaper, yet more capable language models to appear in the near future.
Use LLMs to handle tasks
It is natural to investigate how to harnesses the language competence of current LLMs by utilizing tools like a search engine, an external knowledge base, or a symbolic AI solver to handle tasks. The following are some examples.
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
ChemCrow: Augmenting large-language models with chemistry tools
Note, the ChemCrow authors mention that “However, it is important to emphasize that potential risks may arise for non-experts who lack the chemical reasoning to evaluate results or the proper lab training, as conducting experiments still necessitates thorough laboratory experience.” and the director of the movie trailer mentions that “For those who believe that AI will do everything for you: No!” and “I’ll always prefer to put my own heart & soul in.”
A paper OpenAGI: When LLM Meets Domain Experts proposes Reinforcement Learning from Task Feedback (RLTF), as an attempt to handle many issues in tasks, like the questions of when, what, and how during the process of calling tools and APIs. See also Augmented Language Models: a Survey.
Such “task handling” resonates the modular architecture.
Modular architecture
To approach AGI from language models, the authors of Dissociating language and thought in large language models: a cognitive perspective suggest that, “instead of or in addition to scaling up the size of the models, more promising solutions will come in the form of modular architectures …, like the human brain, integrate language processing with additional systems that carry out perception, reasoning, and planning”. The authors believe that “a model that succeeds at real-world language use would include–—in addition to the core language component–—a successful problem solver, a grounded experiencer, a situation modeler, a pragmatic reasoner, and a goal setter”.
The following figure shows the Soar Cognitive Architecture, from A Standard Model of the Mind. See also, Modular Deep Learning.
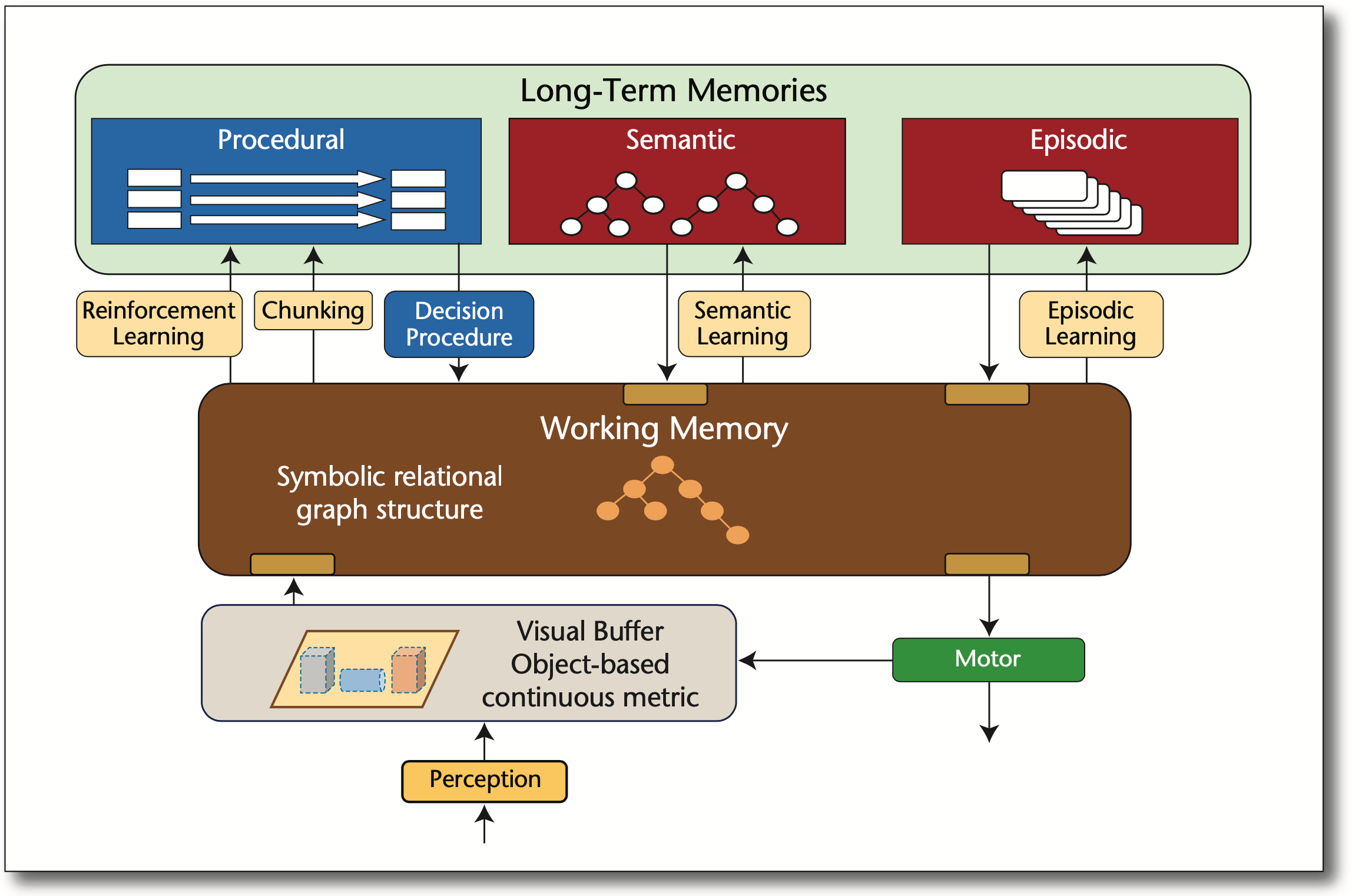
A relevant issue is: should we build a general or a specialized language model?Different (categories of) problems may favour different neural network architectures like different Transformers or even new ones, training data, training algorithms (self-supervised learning, reinforcement learning, etc.). GPT, as it spells out, Generative Pre-trained Transformer, may be best positioned as a pre-trained model, potentially in a general sense; meanwhile, together with specialized models, augmented with memories, handles problems with specialized expertise.
LLMs as autonomous agents?
There are works using LLMs to generate feedback / training data or to build autonomous agents. Examples follow.
This raises the concern: can we treat an LLM, in particular, GPT-4, as an oracle? Let’s first compare AlphaGo with ChatGPT.
AlphaGo vs ChatGPT
The lessons from AlphaGo / AlphaGo Zero / AlphaZero are: 1) imitation learning is far from enough; 2) with a game rule, there is a perfect model, from which we can generate infinite high quality data; 3) it iteratively improves policy, with trial and error, using general policy iteration, by self play.
Previous study use expert games to train a program. However, self play reinforcement learning achieves super-human performance in Go, chess, and shogi from scratch, as shown in AlphaGo, AlphaGo Zero, and AlphaZero, and also in many other games.
Sergey Levine provides more examples to show that imitation learning is far from enough. In a blog Offline RL and Large Language Models, he shows that in a tech support application, RL can learn from several specialists for different aspects to improve the job. In a talk The Bitterest of Lessons: The Role of Data and Optimization in Emergence, he illustrates that RL can stitch parts of policies to attain a better policy.
In AlphaGo, as well as AlphaZero and many games AI, there is a perfect game rule, i.e., the world model, including a perfect feedback. The perfect rule and the perfect feedback, or the perfect world model, support the iterative improvements with self play to achieve a very strong computer program.
ChatGPT does not have such luxury: there is no perfect rule for most, if not all, language problems, neither a perfect feedback. Moreover, the way ChatGPT learns appears as imitation learning, which as discussed above, is not enough.
LLMs == Oracle ???
An oracle is about a world model, a simulator, an agent, being causal, being logical, and the ability of reasoning / planning, in a perfect sense.
Can current LLMs learn a perfect world model? Let’s consider an intuitive scenario. A very smart person, being isolated from the world, has read all the books in the world. She could in her mind build a world model, which however, very likely would be very different from the truth. This may be one cause of hallucination. We can realize that her learning approach is much stronger than “GPT + Internet text data + next token prediction”. If she could watch videos, the world model would become closer to the truth. However, interactions with the world is still lacking.
Jacob Andreas admits that an agent is what we want for human language technologies: “not just a predictive model of text, but one that can be equipped with explicit beliefs and act to accomplish explicit goals”, and emphasizes that current models are only approximations, although he attempts to justify that Language Models as Agent Models.
One question is, how close is such approximation? Moreover, it is highly likely that an LLM performs differently on different tasks, e.g., answering a question vs competing with AlphaZero. How much do we know about the different degrees of approximations for different tasks?
Naturally errors appear with an approximate world model, esp. if far away from the truth. Compounding errors are particularly serious for sequential decision makings. Jokingly yet seriously, an autonomous yet carelessly agent built on a wrong world model may yield an alien civilization like Three Body. Or even something more evil.
Here are some concrete examples. A recent study shows ChatGPT: Jack of all trades, master of none. Another recent study On the Planning Abilities of Large Language Models (A Critical Investigation with a Proposed Benchmark) shows that “LLM's ability to autonomously generate executable plans is quite meager, averaging only about 3% success rate.” One more example. GPT with next token prediction for a “simple” game Othello is still struggling with even generating legal moves, as in an ICLR 2023 paper Emergent world representations: Exploring a sequence model trained on a synthetic task. Meanwhile, games AI has achieved super-human performance. These are with GPT-3 though. It is desirable to study with GPT-4. However, they show the point.
Search engine, knowledge base, and vector database are promising assistants to LLMs. However, these are not perfect yet, thus still not fully reliable. Without perfect rules, the successes of self-play in games AI won’t extend straightforwardly to language models.
We need to bear in mind that current LLMs still make mistakes. We need to handle potential errors, before making it fully autonomous. Ideally, we can make improvements iteratively with feedback.
Make the foundation sound and solid
Humans interact with the world, perceive the world, and transform the world. This is also very likely true for a language model, to improve the world model, and to make the foundation sound and solid, improving grounding for better understanding and agency for goal achieving.
A recent survey about both grounding and agency: Foundation Models for Decision Making: Problems, Methods, and Opportunities. Foundation models are helpful for all components in decision making: states, actions, rewards, transition dynamics, agents, environments, and applications, with generative modeling or representation learning. “Our premise in this report is that research on foundation models and interactive decision making can be mutually beneficial if considered jointly. On one hand, adaptation of foundation models to tasks that involve external entities can benefit from incorporating feedback interactively and performing long-term planning. On the other hand, sequential decision making can leverage world knowledge from foundation models to solve tasks faster and generalize better.”
Google proposes PaLM-E: An Embodied Multimodal Language Model “to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts”, “for multiple embodied tasks, including sequential robotic manipulation planning, visual question answering, and captioning”, and show that “PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains”, and the largest model, PaLM-E-562B, “retains generalist language capabilities with increasing scale”.
See a recent talk Towards a Robotics Foundation Model, with several recent work in robotics leverage leveraging “Bitter Lesson 2.0”.
The bitter lesson
Rich Sutton states in the blog The Bitter Lesson: “The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.” “One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.” Rich also highlights the importance of meta methods.
Sergey Levine discusses the purpose of a language model and how RL can help fulfill it and talks about the role of data and optimization for emergence: “Data without optimization does not allow us to solve problems in new ways.” and “Optimization without data is hard to apply to the real world outside of simulators.”
People may tend to scale up the sizes of the network and the training dataset to achieve better performance, even more “emergent abilities”, refering to The Bitter Lesson as a support. However, “Scaling up is all you need” is a misreading of the Bitter Lesson. For example, scaling up heuristic search algorithms like A* and IDA* won’t achieve a superhuman Go. The collaboration of excellent achievements in deep learning, reinforcement learning, and Monte-Carlo tree search (MCTS), together with powerful computing, set the landmark in AI. See also, A Better Lesson by Rodney Brooks and Engineering AI by Leslie Kaelbling.
A reflection after watching The Imitation Game
Alan Turing during WWII decoded ENIGMA, with search
Deep Blue in 1997 defeated Garry Kasparov, with search
AlphaGo in 2016 defeated Lee Sedol, with learning and search
Rich Sutton in 2019, after pondering 70 years of AI, summarized that two general AI methods that may scale arbitrarily are learning and search
ChatGPT in 2022 accumulated millions of users in a short time, with learning
Next generation language models likely require learning and search
Reinforcement learning gracefully integrates learning and search
See the figure from RL Course by David Silver.

The Increasing Role of Sensorimotor Experience in AI
To avoid more bitter lessons, we may want to listen to Rich Sutton more.
He gave a talk The Increasing Role of Sensorimotor Experience in AI in February 2022. The following is from the talk.
Sensorimotor experience is the sensations and actions of an agent’s ordinary interaction with the world. Over AI’s seven decades, experience has played an increasing role; four major steps in this progression.
Step 1: Agenthood (having experience, sensation & action)
Step 2: Reward (goals in terms of experience)
Step 3: Experiential state (state in terms of experience)
Step 4: Predictive knowledge (to know is to predict experience, perception)
state-to-experience prediction (value functions)
state-to-state (transition model)
For each step, AI has reluctantly moved toward experience in order to be more grounded, learnable and scalable.


The figures are from the talk and the paper The quest for a common model of the intelligent decision maker. Rich Sutton proposes the common model of the intelligent agent, a perspective on the decision maker that is substantive and widely held across psychology, AI, economics, control theory, and neuroscience. This is essentially similar to Yann LeCun’s Autonomous Machine Intelligence.
There have long standing debates about nature vs nurture, empiricism vs rationalism, and connectionism vs symbolism. The common model of the intelligent decision making integrates experience with model, which reconciles nature with nurture, empiricism with rationalism, and connectionism with symbolism, and consequently paves the way for sound and solid grounding and agency.
Case studies with reinforcement learning
Reinforcement learning from human feedback (RLHF) plays a critical role in human alignment and facilitates learning of the objective function, the single most important ingredient for all optimization tasks. OpenAI ChatGPT collects human data. Deepmind Sparrow: Improving alignment of dialogue agents via targeted human judgements and Anthropic Constitutional AI: Harmlessness from AI Feedback design rules and reduce the reliance on human involvements.
Games to AI is like fruit flies to genetics. Games AI, in particularly with RL, is promising to push LLMs and AI further. See e.g., Human-level play in the game of Diplomacy by combining language models with strategic reasoning and Building Open-Ended Embodied Agents with Internet-Scale Knowledge.
Programming language is more formal and thus relatively easier than natural language. Moreover, we may utilize an interpreter to help judge the correctness and quality of generated codes. See e.g., CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning, Planning with Large Language Models for Code Generation, and Language Models Can Teach Themselves to Program Better.
As the authors of Offline RL for Natural Language Generation with Implicit Language Q Learning claim, the proposed method satisfies the following conditions to make RL practical for LLMs: easy to use, able to optimize user specified rewards, practical in interactive settings, able to leverage existing data, and temporally compositional.
RL is also applied to prompt optimization / automation, e.g., RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning and TEMPERA: Test-Time Prompting via Reinforcement Learning.
Social interaction is critical for language models. RL integrates with social learning, e.g., Socially situated AI enables learning from human interaction and Emergent Social Learning via Multi-agent Reinforcement Learning. See also Social Neuro AI: Social Interaction as the “Dark Matter” of AI.
Excitingly, there are already foundation models for RL, e.g. Adaptive Agent (AdA) Human-Timescale Adaptation in an Open-Ended Task Space and SMART: Self-supervised Multi-task pretrAining with contRol Transformers. It is an inspiring starting point for RL generalists targeting various applications, e.g., in one or several areas of operations research, optimal control, economics, finance, and computer systems.
See the survey: Foundation Models for Decision Making: Problems, Methods, and Opportunities.
Iterative improvements from feedback
As a conclusion, reinforcement learning is all you need, for next generation language models, with sound and solid grounding and agency, through iterative improvements from feedback, by interactions with the physical and social world.
This requires valuable and reliable feedback or signal or reward, with sample- / time- / space-efficient algorithms, considering safety and ethics.
Epilogue
Reinforcement learning has remarkable achievements like AlphaGo, ChatGPT,
A Contextual-Bandit Approach to Personalized News Article Recommendation,
Horizon: The first open source reinforcement learning platform for large-scale products and services,
Ride-hailing order dispatching at DiDi via reinforcement learning,
Grandmaster level in StarCraft II using multi-agent reinforcement learning,
DeepStack: Expert-level artificial intelligence in heads-up no-limit poker,
Superhuman AI for heads-up no-limit poker: Libratus beats top professionals,
Human-level play in the game of Diplomacy by combining language models with strategic reasoning,
Outracing champion Gran Turismo drivers with deep reinforcement learning,
Magnetic control of tokamak plasmas through deep reinforcement learning
AlphaTensor: Discovering faster matrix multiplication algorithms with reinforcement learning.
However, we may still have the question: Why has RL not been widely adopted in practice yet? As the figure below shows, there is a big chicken-egg loop: no killer application, insufficient appreciation from higher management, insufficient resources, insufficient R&D, slow adoption, then, as a result, non-trivial to have a killer application. There are underlying challenges from education, research, development and business. The status quo is actually much better, having many success stories, with several examples above. With challenges, RL is promising. (The statement and the figure are from Reinforcement Learning in Practice: Opportunities and Challenges.) Will language models be a killer app for reinforcement learning?

Reinforcement learning from human feedback is indispensable for the success of ChatGPT. RLHF is critical, esp. for human value alignment. However, the discussion above shows that RLHF is an appetizer, while RL is the main course.
Important things deserve repeating many times: Iterative improvements from feedback are paramount for language models. Reinforcement learning is the natural and right framework for learning from interactions. Reinforcement learning is all you need, for next generation language models.
Acknowledgement
Thanks Prof. Peter Stone for great feedback.
Couldn't agree more. Your insight on applying AlphaGo's RL approach to LLMs is realy spot on. The grounding and agency argument feels like the key for next-gen models. Fantastic read!
thx for more info about LLM with RL :)