


Where is the boundary for large language models?

Large language models (LLMs), like OpenAI ChatGPT and Google LaMDA, are impressive, being competent in many aspects. At the same time, LLMs are incompetent in many ways. LLMs are evolving, and new players are joining. How to make assessments? What further progress may be possible?
Moreover, we may ask a question relevant to almost all players in the world of LLMs, from students, researchers, engineers, entrepreneurs, venture capitalists, officers, to the public crowd: Where is the boundary for large language models?
Executive summary
Five levels of World Scopes — corpus, Internet, perception, embodiment, social — “go beyond text to the contextual foundations of language: grounding, embodiment, and social interaction”.
The ultimate goal of a language is for communication, esp. among people. Next token prediction trained with only texts misaligns with such a goal.
Next token prediction with GPT is not enough, at least for many games, for which reinforcement learning methods have achieved super-human performance.
LLMs trained with only texts will likely encounter dimensionality reduction strikes from LLMs armed with grounding and agency from multimodality, embodiment, and social interaction.
Reinforcement learning appears as a solution.
In AI Stores, an AI models provider may eat the business territories of downstream model users.
Five levels of World Scopes
First, we discuss the five levels of World Scopes in the paper Experience Grounds Language (EMNLP 2020), which argues that “Language understanding research is held back by a failure to relate language to the physical world it describes and to the social interactions it facilitates”.
WS1. Corpus (our past). Corpora and Representations. Small scale.
WS2. Internet (most of current NLP). The Written World. Large scale.
WS3. Perception (multimodal NLP). The World of Sights and Sounds.
WS4. Embodiment. Embodiment and Action. Interaction with physical world.
WS5. Social. The Social World. Interaction with human society.
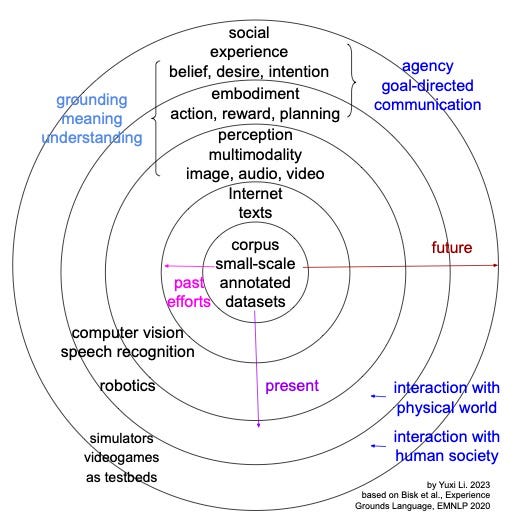
The authors posit that “These World Scopes go beyond text to consider the contextual foundations of language: grounding, embodiment, and social interaction.” Grounding is about meaning and understanding. Embodiment is about interaction, with action, reward and planning, in particular, in a physical world. Social interaction is about communication in human society. Agency is about, with belief, desire and intention, acting to achieve goals.
WS2 is subset of WS3: “You can’t learn language from the radio (Internet).” “A task learner cannot be said to be in WS3 if it can succeed without perception (e.g., visual, auditory). ” “Computer vision and speech recognition are mature enough for investigation of broader linguistic contexts (WS3).”
WS3 is subset of WS4: “You can’t learn language from a television.” “A task learner cannot be said to be in WS4 if the space of its world actions and consequences can be enumerated.” “The robotics industry is rapidly developing commodity hardware and sophisticated software that both facilitate new research and expect to incorporate language technologies (WS4).”
WS4 is subset of WS5: “You can’t learn language by yourself.” “A task learner cannot be said to be in WS5 unless achieving its goals requires cooperating with a human in the loop.” “Simulators and videogames provide potential environments for social language learners (WS5).”
The authors postulate that “the present success of representation learning approaches trained on large, text-only corpora requires the parallel tradition of research on the broader physical and social context of language to address the deeper questions of communication”, and encourage “the community to lean in to trends prioritizing grounding and agency, and explicitly aim to broaden the corresponding World Scopes available to our models”.
Current LLMs may approximate agent models
On the positive side, current LLMs may be helpful to some extent. Actually, ChatGPT Hits 100 Million Users, Google Invests In AI Bot And CatGPT Goes Viral. On the negative side, they may still be inherently insufficient.
The following two papers argue that sequence modeling is fundamentally limiting, from philosophical and mathematical perspectives, respectively: Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data and Provable Limitations of Acquiring Meaning from Ungrounded Form: What Will Future Language Models Understand?
Jacob Andreas admits that an agent is what we want for human language technologies: “not just a predictive model of text, but one that can be equipped with explicit beliefs and act to accomplish explicit goals”, and emphasizes that current models are only approximations, although he attempts to justify that Language Models as Agent Models. It appears that the author’s thesis is: Given the current best practice, in particular, next token prediction trained with text-only Internet data with GPT, we should benefit from it as much as possible. As a community, it is desirable to look ahead and look deeper, searching for the best architecture and mechanism.
A concrete example is an ICLR 2023 paper Emergent world representations: Exploring a sequence model trained on a synthetic task. Games to AI is like fruit flies to genetics. The authors use Othello as the testbed to study an emergent world model to predict legal moves after developing the specialized model Othello-GPT, and to validate the state representation by probing internal network activations, with experiments and latent saliency maps.
Such studies have their merits. However, natural questions are: Is GPT enough? Can we do better? One critical factor is the agency discussed above. As shown in the MuZero paper by Deepmind published in Nature in 2020, an agent is capable of Mastering Atari, Go, chess and shogi by planning with a learned model with no a priori knowledge of game rules.
For many games, while GPT with next token prediction is still struggling with even generating legal moves, reinforcement learning methods with the architecture of agent, environment, state, action, and reward, have already achieved super-human performance, likely with a better world model. Moreover, excitedly, efforts have started building foundations models for reinforcement learning. Deepmind propose adaptive agent (AdA): Human-Timescale Adaptation in an Open-Ended Task Space. Microsoft proposes SMART- Self-supervised Multi-task pretrAining with contRol Transformers. A natural question is: Can we scale reinforcement learning methods, like MuZero, AdA, or SMART, to that like the Internet?
We may extrapolate that current LLMs to predict next token trained with text-only data will likely encounter “dimensionality reduction strikes”, from LLMs armed with grounding and agency from multimodality, embodiments, and social interactions.
Language modelling is very complex
Language modelling is a very complex multi-objective optimization problem, with many objectives, e.g., groundedness, safety, unbiasedness, sensibleness, specificity, and interestingness. Many factors, like culture, history, psychology, and philosophy, play their roles. Different users have different or even contradictory perspectives. How to handle ethical issues, e.g., those raised in You Are Not a Parrot. And a chatbot is not a human. and AI Chatbots Don’t Care About Your Social Norms? Should we expect a general language model to be optimal for all objectives and for all users, approximately or in a Pareto sense? These are open questions.
Success stories
Success stories of current LLMs
Ethan Mollick discusses the success of current LLMs in the blog Secret Cyborgs: The Present Disruption in Three Papers. Ethan starts with two controlled experiments. From the paper The Impact of AI on Developer Productivity: Evidence from GitHub Copilot, Ethan observes that an increase of 55.8% in productivity when using AI for programming. From the paper Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence, Ethan observes that professionals with ChatGPT completing tasks like realistic memos, strategy documents and policies 37% faster, with better average writing quality. Ethan then discusses which jobs face most exposure to AI based on the paper How will Language Modelers like ChatGPT Affect Occupations and Industries?, and observes that the list includes academics, teachers, psychologists, and lawyers from large industries and highly-skilled jobs.
OpenAI, Anthropic, and Deepmind, among others, are making efforts to pursue social interactions, however, without multimodality and embodiments yet.
OpenAI ChatGPT has the ingredients for human-in-the-loop with supervised fine-tuning, reinforcement learning from human feedback (RLHF), and iterative deployment from user feedback.
Anthropic proposes Constitutional AI: Harmlessness from AI Feedback, with supervised learning by self-critiques and revisions, and reinforcement learning from AI feedback (RLAIF), using a list of manually designed rules or principles, without human feedback labels for harms.
Deepmind proposes Sparrow, an information-seeking dialogue agent, use RLHF with rule-based rewards, by breaking down “the requirements for good dialogue into natural language rules the agent should follow” and asking “raters about each rule separately”, and by providing evidence to support factuality.
Success stories pursuing the World Scopes
A recent survey about both grounding and agency: Foundation Models for Decision Making: Problems, Methods, and Opportunities. Foundation models are helpful for all components in decision making: states, actions, rewards, transition dynamics, agents, environments, and applications, with generative modeling or representation learning.“Our premise in this report is that research on foundation models and interactive decision making can be mutually beneficial if considered jointly. On one hand, adaptation of foundation models to tasks that involve external entities can benefit from incorporating feedback interactively and performing long-term planning. On the other hand, sequential decision making can leverage world knowledge from foundation models to solve tasks faster and generalize better.”
To address grounding, Google proposes PaLM-E: An Embodied Multimodal Language Model “to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts”, “for multiple embodied tasks, including sequential robotic manipulation planning, visual question answering, and captioning”, and show that “PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains”, and the largest model, PaLM-E-562B with 562B parameters, “retains generalist language capabilities with increasing scale”.
OpenAI introduces CLIP: Connecting text and images. Google introduces Vision Transformer (ViT). There are several popular tools generating images from texts, e.g., OpenAI DALL·E 2, Stable Diffusion, and Midjourney.
OpenAI introduces Whisper in the paper Robust Speech Recognition via Large-Scale Weak Supervision. Google introduces USM:Scaling Automatic Speech Recognition Beyond 100 Languages and MusicLM: Generating Music From Text. Deepmind introduces Flamingo: a Visual Language Model for Few-Shot Learning. Microsoft proposes Multimodal Large Language Model (MLLM) in the paper Language Is Not All You Need: Aligning Perception with Language Models (Github) and Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models. And a recent study: Aligning Text-to-Image Models using Human Feedback.
AI Stores vs App Stores
AI Stores will plausibly be the paradigm in the era of large language models (LLMs), or foundation models in general. An AI Store is an ecosystem, hosting one or more general AI models and many specialized AI models, providing convenient user interfaces. Researchers and developers refine their models, either with API calls as retails, or with model fine-tunings as whole sales.
It is naturally incentivized for AI models providers to keep improving models’ capacities. AI models may expand their capacities 1) horizontally by prompting automation, 2) horizontally by integrating tools, and / or 3) vertically by incorporating common blocks for specialized domains. LLMs will improve, likely adeptly and significantly, esp. at the current stage, in the beginning and many giants are joining. As a result, unfortunately, AI models providers may eat the business territories of downstream model users. This is different from App Stores.
We need to watch / estimate the progress in LLMs, so that we have a moat wide and deep enough for defence against potential invasions to our business territories from not only competitors but also platform providers. The question remains: How to make such judgements?
Epilogue
We are entering the era of foundation models. Let’s make the foundation sound and solid. The ultimate boundary for LLMs is AGI. We have a discussion here: Will AGI Emerge from Large Language Models? LLMs need to handle the long-standing issues of nature versus nurture, empiricism versus rationalism, and connectionism versus symbolism, on the journey pursuing grounding and agency, by incorporating multimodality, embodiments, and social interactions. Reinforcement learning appears as a solution.