
Autonomous agent is a BIG bubble

Executive summary
Autonomous agent is still an open problem in AI.
Agency/planning is a pre-requisite.
Agency is achieved by interactions with the world.
Most LMs do not consider agency/planning during pre-training.
Self-play works for games AI like AlphaGo due to perfect game rules.
All LMs are imperfect.
“Self-play” based on an imperfect model will cause problems.
We should never deploy a robot trained fully in simulator.
Autonomous agent is still an open problem in AI
People are talking about autonomous agent based on language models (LMs), like AutoGPT and BabyAGI. The author of BabyAGI admitted that “A general autonomous agent, that can be given any reasonable objective and accomplish it well… well, we’re far from that.”
The reason is fundamental: most LMs are not trained for agency/planning. Agency is about goal-directed behaviour, which is essential to AI. Autonomous agent is still an open problem in AI, unless AI is solved.
Approximate models will cause problems
The author of the paper Language Models as Agent Models emphasizes that current LMs are only approximations. Such approximate models will cause problems.
One example is Emergent world representations: Exploring a sequence model trained on a synthetic task (ICLR 2023), where OthelloGPT with next token prediction is still struggling with generating legal moves. Another example is Tree of Thoughts: Deliberate Problem Solving with Large Language Models, where GPT-4 plus the advanced technique ToT can not fully solve problems as simple as Game of 24.
Even games AI are still exploitable
Games AI, e.g., AlphaGo, can use self-play to make iterative improvements due to perfect game rule or model and perfect feedback. Moreover, as shown in the MuZero paper by Deepmind published in Nature in 2020, an agent is capable of Mastering Atari, Go, chess and shogi by planning with a learned model with no a priori knowledge of game rules.
Even so, a recent study shows that superhuman games AI is still exploitable. A system is always exploitable, before reaching optimal, i.e., Nash equilibrium or the minimax solution for two-player zero-sum games.
A straightforward implication: Autonomous agent based on the current LMs are very brittle.
As an example, if the game in Generative agents: Interactive simulacra of human behavior relies on an imperfect LM and does not improve it, it is unclear what kind of human society it may build. Even a random walk can build a civilization anyways. A key issue is: how well does an LM simulate humans?
A side story: autonomous driving
In Nov 2018, I wrote a blog: Fully Self-driving Vehicles Aren’t Ready For Road Tests Yet, after reading that Insurance Institute for Highway Safety (IIHS) shows that human drivers in US encounter roughly one death per 100 million vehicle miles. The first two sentences are still valid now. “The current science, engineering, and technology, including artificial intelligence (AI), are not sufficient for fully self-driving vehicles to operate on roads yet. For self-driving vehicles, assistance from human drivers is still indispensable.” A nice feature for many autonomous agent applications is, mistakes may not have serious consequences as in autonomous driving.
Some KOLs supporting autonomous driving then are now KOLs supporting autonomous agent.
Look back a little bit further, there was the .com bubble.
Pre-training is pre-training
Pre-training models are for many potential downstream tasks. Besides limitations of learning from next token prediction, there are fundamental issues from basic optimization principles:
Multi-objective optimization usually can not optimize all objectives.
For a multi-constraint problem, the more and the tighter constraints, the less chance to find a feasible solution.
This leads straightforwardly to the conclusion: AGI is a wrong goal.
Pre-training then fine-tuning is a normal pipeline. Fine-tuning will likely improve performance than calling APIs of a pre-trained model.
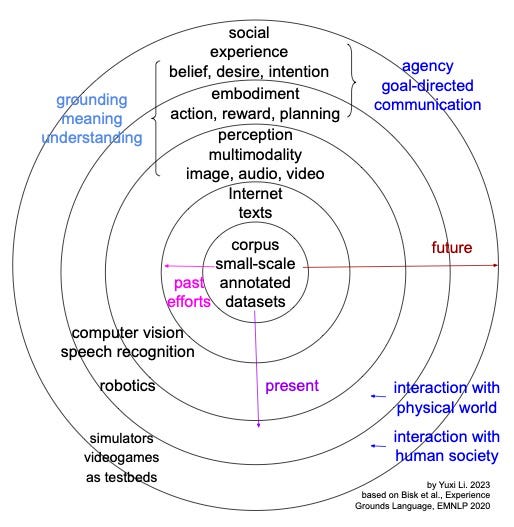
Agency is achieved by interactions with the world
As discussed in Experience Grounds Language (EMNLP 2020), agency is achieved by interacting with physical and social world, beyond World Scopes of labeled texts, Internet texts and multimodality. We can not learning swimming by only reading books. For more detail, see a blog, or even better, a manuscript.
It may be possible to fine-tune LMs like GPT-4 or LLaMA 2 for better planning competence, esp. for a particular task or a set of tasks. However, these models are not trained for agency/planning.
There are recent work considering agency/planning during pre-training, e.g., Gato: A Generalist Agent, Adaptive Agent: Human-Timescale Adaptation in an Open-Ended Task Space, RT-1: Robotics Transformer for Real-World Control at Scale, and SMART: Self-supervised multi-task pretraining with control transformers.
Look forward to the success of these or similar models for further progress in autonomous agent. Let’s respect ground-truth-in-the-loop, bridge the LM-to-real gap, and make iterative improvements from feedback.