Q* is a standard jargon in reinforcement learning (RL) for optimal Q value. Reinforcement learning integrates learning and search, which are powerful AI techniques, with AlphaGo as an example.
A brief introduction to reinforcement learning

An RL agent interacts with the environment over time to learn a policy, by trial and error, that maximizes the long-term, cumulated reward. At each time step, the agent receives an observation, selects an action to be executed in the environment, following a policy, which is the agent’s behaviour, i.e., a mapping from an observation to actions. The environment responds with a scalar reward and by transitioning to a new state according to the environment dynamics. The figure illustrates the agent-environment interaction.
A state or action value function measures the goodness of each state or state action pair, respectively. It is a prediction of the return, or the expected, accumulative, discounted, future reward. The action value function is usually called the Q function. An optimal value is the best value achievable by any policy, and the corresponding policy is an optimal policy. An optimal value function encodes global optimal information, i.e., it is not hard to find an optimal policy based on an optimal state value function, and it is straightforward to find an optimal policy with an optimal action value function. The agent aims to maximize the expectation of a long-term return or to find an optimal policy.
TD learning and Q-learning are value-based methods. In contrast, policy-based methods optimize the policy directly, e.g., policy gradient. Actor-critic algorithms update both the value function and the policy.
The following illustrates Q-learning algorithms. Let’s see if it self-explains.


Learning and Search
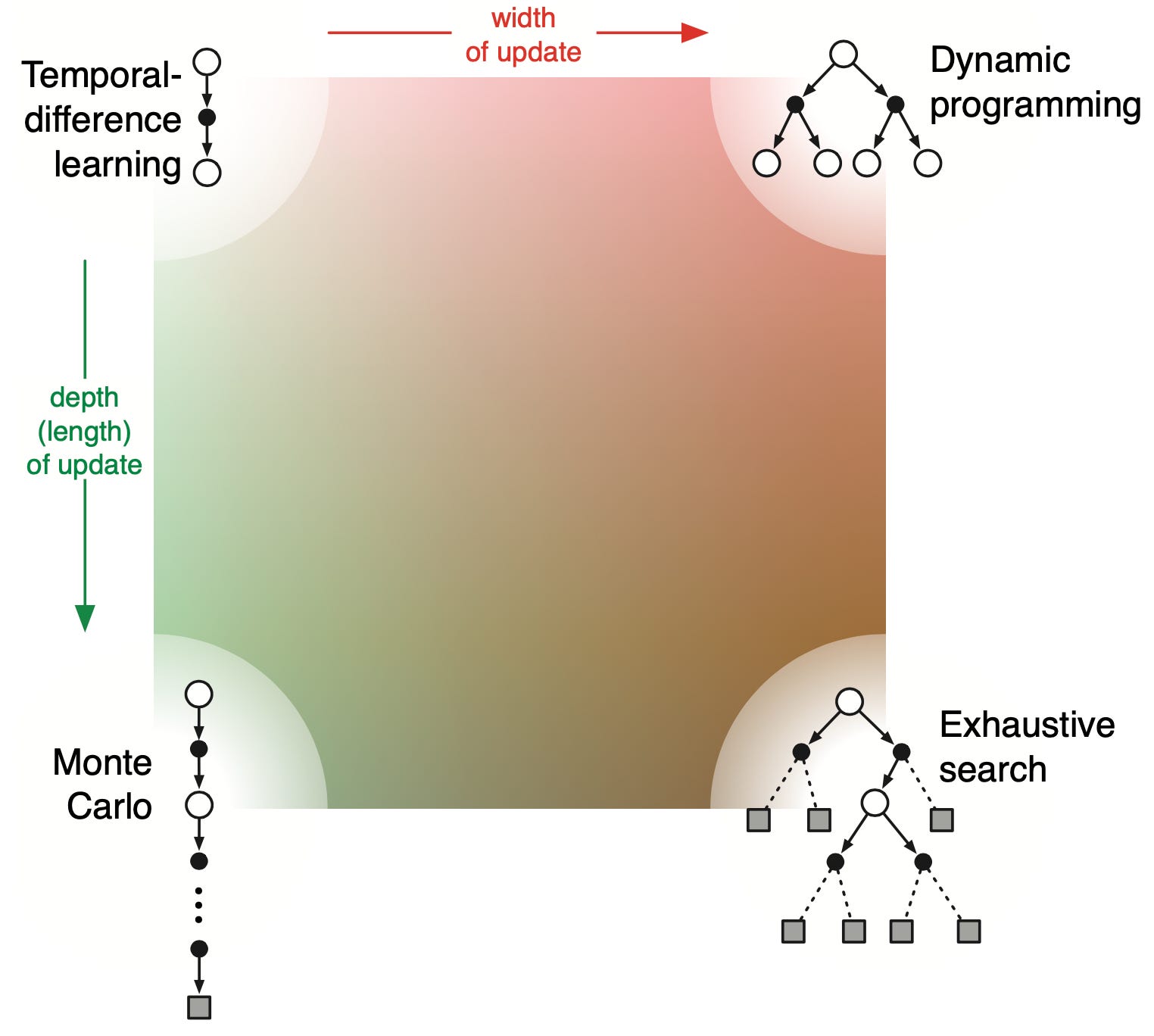
RL integrates learning and search, with respect to both depth and width of value function update, covering Temporal Difference learning, dynamic programming, Monte Carlo and exhaustive search (including heuristic search algorithms like A*).
Rich Sutton states in the blog The Bitter Lesson: “The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.” “One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.” Rich also highlights the importance of meta methods.
Sergey Levine discusses the purpose of a language model and how RL can help fulfill itand talks about the role of data and optimization for emergence: “Data without optimization does not allow us to solve problems in new ways.” and “Optimization without data is hard to apply to the real world outside of simulators.”
People may tend to scale up the sizes of the network and the training dataset to achieve better performance, even more “emergent abilities”, refering to The Bitter Lesson as a support. However, “Scaling up is all you need” is a misreading of the Bitter Lesson. For example, scaling up heuristic search algorithms like A* and IDA* won’t achieve a superhuman Go. The collaboration of excellent achievements in deep learning, reinforcement learning, and Monte-Carlo tree search (MCTS), together with powerful computing, set the landmark in AI. See also, A Better Lesson by Rodney Brooks and Engineering AI by Leslie Kaelbling.
A reflection after watching The Imitation Game
Alan Turing during WWII decoded ENIGMA, with search
Deep Blue in 1997 defeated Garry Kasparov, with search
AlphaGo in 2016 defeated Lee Sedol, with learning and search
Rich Sutton in 2019, after pondering 70 years of AI, summarized that two general AI methods that may scale arbitrarily are learning and search
ChatGPT in 2022 accumulated millions of users in a short time, with learning
Next generation language models likely require learning and search
Reinforcement learning gracefully integrates learning and search
Learning + Search or RL for LLMs?
Sure!
I talked about this before.
A preprint (likely the best survey about RL for LLMs; ask me for an updated version):
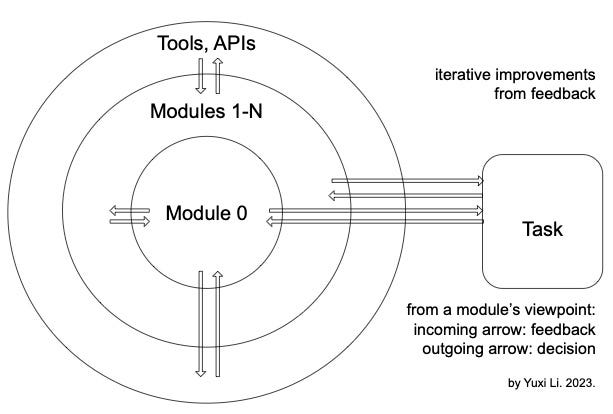
Iterative improvements from feedback for language models
A blog:
Reinforcement learning is all you need, for next generation language models.
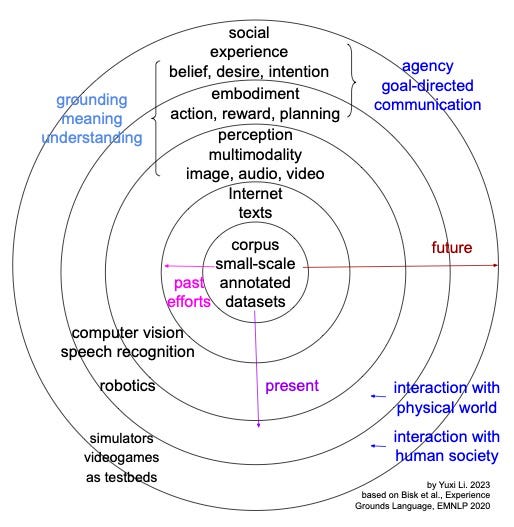
The following figures say a lot about applying RL to LLMs.